本博文为2023秋季学期续本达老师开设的"概率统计分析与量测技术"课程的笔记.该课程的课件资源与视频资源可在此网站找到:https://hep.tsinghua.edu.cn/~orv/teaching/statistics/
博主本来在hedgedoc编辑本文,但是非常铸币地使用了demo版编辑.于是在编辑完后的第二天,博主惊奇地发现自己的博文已经化为乌有且没有备份,无奈转战hexo,大家引以为戒.(QAQ)
L1 课程介绍,随机事件
(待补)
L2 概率定义与解释
(待补)
L3 条件概率与独立事件
(待补)
L4 随机变量与分布
(待补)
L5 连续性随机变量
(待补)
L6 随机变量的函数
首先介绍一些上节课没说完的连续性随机变量分布:
6.1 伽马分布
伽马分布定义
若随机变量X X X
f ( x ; α , λ ) = λ α Γ ( α ) x α − 1 e − λ x , x ≥ 0 f(x;\alpha,\lambda)=\frac{\lambda^\alpha}{\Gamma(\alpha)}x^{\alpha-1}e^{-\lambda x},x\geq 0 f ( x ; α , λ ) = Γ ( α ) λ α x α − 1 e − λ x , x ≥ 0
α > 0 , λ > 0 \alpha>0,\lambda>0 α > 0 , λ > 0 X X X 伽马分布 ,记作:X ∼ G a ( α , λ ) X\sim Ga(\alpha,\lambda) X ∼ G a ( α , λ )
如果不熟悉的话,伽马函数 的定义为:
Γ ( α ) = ∫ 0 ∞ x α − 1 e − x d x \Gamma(\alpha)=\int_0^{\infty}x^{\alpha-1}e^{-x}dx
Γ ( α ) = ∫ 0 ∞ x α − 1 e − x d x
其中要求α > 0 \alpha>0 α > 0
伽马函数的一些重要的性质:
Γ ( 1 ) = 1 , Γ ( 1 2 ) = π \Gamma(1)=1,\Gamma(\frac12)=\sqrt{\pi} Γ ( 1 ) = 1 , Γ ( 2 1 ) = π 若n n n Γ ( n + 1 ) = n ! \Gamma(n+1)=n! Γ ( n + 1 ) = n !
伽马分布性质
伽马分布的性质有:
G a ( 1 , λ ) = E x p ( λ ) Ga(1,\lambda)=Exp(\lambda) G a ( 1 , λ ) = E x p ( λ )
可加性:
若X 1 ∼ G a ( α 1 , λ ) , X 2 ∼ G a ( α 2 , λ ) X_1\sim Ga(\alpha_1,\lambda),X_2\sim Ga(\alpha_2,\lambda) X 1 ∼ G a ( α 1 , λ ) , X 2 ∼ G a ( α 2 , λ ) X 1 + X 2 ∼ G a ( α 1 + α 2 , λ ) X_1+X_2\sim Ga(\alpha_1+\alpha_2,\lambda) X 1 + X 2 ∼ G a ( α 1 + α 2 , λ )
证明留到L8.
这一性质是针对参数α \alpha α 形状参数 .
伸缩自相似性:
f ( x ; α , λ ) d x = f ( λ x ; α , 1 ) d ( λ x ) f(x;\alpha,\lambda)dx=f(\lambda x;\alpha,1)d(\lambda x) f ( x ; α , λ ) d x = f ( λ x ; α , 1 ) d ( λ x )
证明:
L H S = λ α Γ ( α ) x α − 1 e − λ x d x = 1 Γ ( α ) ( λ x ) α − 1 e − λ x d ( λ x ) = R H S \begin{aligned} LHS &= \frac{\lambda^\alpha}{\Gamma(\alpha)}x^{\alpha-1}e^{-\lambda x}dx\\ &= \frac{1}{\Gamma(\alpha)}(\lambda x)^{\alpha-1}e^{-\lambda x}d(\lambda x)\\ &= RHS\end{aligned} L H S = Γ ( α ) λ α x α − 1 e − λ x d x = Γ ( α ) 1 ( λ x ) α − 1 e − λ x d ( λ x ) = R H S
这一性质是针对参数λ \lambda λ 速率参数 .(回忆泊松分布,是不是很像?)
与泊松分布共轭
回忆泊松分布的分布列:
P ( X = k ) = λ k k ! e − λ , k = 0 , 1 , 2 , . . . P(X=k)=\frac{\lambda^k}{k!}e^{-\lambda},k=0,1,2,...
P ( X = k ) = k ! λ k e − λ , k = 0 , 1 , 2 , ...
我们在泊松分布中固定了参数λ \lambda λ k k k k k k λ \lambda λ λ ∼ G a ( k + 1 , 1 ) \lambda\sim Ga(k+1,1) λ ∼ G a ( k + 1 , 1 ) 共轭关系 会在下半学期的贝叶斯分析中得到进一步应用.
R语言绘图
(?)
6.2 卡方分布
卡方分布定义
若随机变量X X X
f ( x ; n ) = x n / 2 − 1 2 n / 2 Γ ( n / 2 ) e − x 2 , x ≥ 0 f(x;n)=\frac{x^{n/2-1}}{2^{n/2}\Gamma(n/2)}e^{-\frac{x}{2}},x\geq 0 f ( x ; n ) = 2 n /2 Γ ( n /2 ) x n /2 − 1 e − 2 x , x ≥ 0
其中n n n X ∼ G a ( n 2 , 1 2 ) X\sim Ga(\frac{n}{2},\frac{1}{2}) X ∼ G a ( 2 n , 2 1 ) X X X 卡方分布 ,记作:X ∼ χ 2 ( n ) X\sim \chi^2(n) X ∼ χ 2 ( n )
卡方分布其实就是某种特殊的伽马分布,但它在数理统计中有特殊的地位.
例6.1 (χ 2 ( 1 ) \chi^2(1) χ 2 ( 1 )
f ( x ) = 1 2 π x e − x 2 , x ≥ 0 f(x)=\frac{1}{\sqrt{2\pi x}}e^{-\frac x2},x\geq 0 f ( x ) = 2 π x 1 e − 2 x , x ≥ 0
虽然lim x → 0 + f ( x ) = + ∞ \lim_{x\to 0_+}f(x)=+\infty lim x → 0 + f ( x ) = + ∞ lim x → 0 + ∫ 0 x f ( x ) d x = 0 \lim_{x\to 0_+}\int_0^xf(x)dx=0 lim x → 0 + ∫ 0 x f ( x ) d x = 0 F ( x ) F(x) F ( x )
卡方分布的构造
卡方分布可以用一组满足正态分布的独立随机变量平方和来构造:
对于一组满足标准正态分布的随机变量X 1 , X 2 , . . . , X n ∼ N ( 0 , 1 ) X_1,X_2,...,X_n\sim N(0,1) X 1 , X 2 , ... , X n ∼ N ( 0 , 1 )
X 1 2 + X 2 2 + . . . + X n 2 ∼ χ 2 ( n ) X_1^2+X_2^2+...+X_n^2\sim \chi^2(n)
X 1 2 + X 2 2 + ... + X n 2 ∼ χ 2 ( n )
证明思路:
首先证明X 1 2 ∼ χ 2 ( 1 ) X_1^2\sim \chi^2(1) X 1 2 ∼ χ 2 ( 1 )
R语言绘图
(?)
6.3 贝塔分布
贝塔分布定义
若随机变量X X X
f ( x ; a , b ) = 1 B ( a , b ) x a − 1 ( 1 − x ) b − 1 , 0 < x < 1 f(x;a,b)=\frac{1}{\Beta(a,b)}x^{a-1}(1-x)^{b-1},0<x<1 f ( x ; a , b ) = B ( a , b ) 1 x a − 1 ( 1 − x ) b − 1 , 0 < x < 1
a > 0 , b > 0 a>0,b>0 a > 0 , b > 0 X X X 贝塔分布 ,记作:X ∼ B e ( a , b ) X\sim Be(a,b) X ∼ B e ( a , b )
如果不熟悉的话,贝塔函数 的定义为:
B ( a , b ) = ∫ 0 1 x a − 1 ( 1 − x ) b − 1 d x \Beta(a,b)=\int_0^{1}x^{a-1}(1-x)^{b-1}dx
B ( a , b ) = ∫ 0 1 x a − 1 ( 1 − x ) b − 1 d x
其中要求α > 0 \alpha>0 α > 0
贝塔函数的一些重要的性质:
B ( a , b ) = B ( b , a ) \Beta(a,b)=\Beta(b,a) B ( a , b ) = B ( b , a ) B ( a , b ) = Γ ( a ) Γ ( b ) Γ ( a + b ) \Beta(a,b)=\frac{\Gamma(a)\Gamma(b)}{\Gamma(a+b)} B ( a , b ) = Γ ( a + b ) Γ ( a ) Γ ( b )
贝塔分布性质
贝塔分布性质有:
B e ( 1 , 1 ) = U ( 0 , 1 ) Be(1,1)=U(0,1) B e ( 1 , 1 ) = U ( 0 , 1 )
f ( x ; a , b ) d x = − f ( 1 − x ; b , a ) d x f(x;a,b)dx=-f(1-x;b,a)dx f ( x ; a , b ) d x = − f ( 1 − x ; b , a ) d x
(可见,如果a = b a=b a = b x = 1 2 x=\frac{1}{2} x = 2 1
与二项分布共轭
回忆二项分布分布列:
P ( X = k ) = ( n k ) p k ( 1 − p ) n − k P(X=k)=\begin{pmatrix}
n \\ k
\end{pmatrix}p^k(1-p)^{n-k} P ( X = k ) = ( n k ) p k ( 1 − p ) n − k
在二项分布中固定了参数n , p n,p n , p k k k n , k n,k n , k p p p p ∼ B e ( k + 1 , n − k + 1 ) p\sim Be(k+1,n-k+1) p ∼ B e ( k + 1 , n − k + 1 )
本例中,我们能直观看出p p p n n n k k k p p p
R语言绘图
(?)
6.4 柯西分布和朗道分布
这两个分布是一般的统计学课上不怎么研究的,然而工物系的实验里、粒子物理和核物理领域中它们是常客.
柯西分布
若X X X
f ( x ) = 1 π 1 1 + x 2 , − ∞ < x < + ∞ f(x)=\frac{1}{\pi}\frac{1}{1+x^2},-\infty<x<+\infty f ( x ) = π 1 1 + x 2 1 , − ∞ < x < + ∞
则称X X X 柯西分布 .
这个分布的性质不是很好,其期望、方差均不收敛.但在粒子物理中经常遇到,即大名鼎鼎(?)的布莱特-魏格纳分布 .
例6.2 (布莱特-魏格纳分布,Breit-Wigner)
粒子物理中该分布描述不稳定粒子的质量分布,形式为:
f ( x , m 0 , Γ ) = 1 π Γ / 2 Γ 2 / 4 + ( x − m 0 ) 2 , − ∞ < x < + ∞ f(x,m_0,\Gamma)=\frac{1}{\pi}\frac{\Gamma/2}{\Gamma^2/4+(x-m_0)^2},-\infty<x<+\infty f ( x , m 0 , Γ ) = π 1 Γ 2 /4 + ( x − m 0 ) 2 Γ/2 , − ∞ < x < + ∞
其中m m m Γ \Gamma Γ
朗道分布
速度为β = v c \beta=\frac{v}{c} β = c v d d d Δ \Delta Δ 朗道分布 .分布形式很复杂,不展开介绍了,以下仅供观瞻:
f ( Δ ; β ) = 1 ξ Φ ( λ ( Δ ) ) f(\Delta;\beta)=\frac{1}{\xi}\Phi(\lambda(\Delta))
f ( Δ ; β ) = ξ 1 Φ ( λ ( Δ ))
其中:
Φ ( λ ) = 1 π ∫ 0 ∞ e − u ( log u + λ ) sin ( π u ) d u λ ( Δ ) = 1 ξ [ Δ − ξ ( log ξ ϵ ′ + 1 − 1 1 − β 2 ) ] \Phi(\lambda)=\frac{1}{\pi}\int_0^{\infty}e^{-u(\log{u}+\lambda)}\sin({\pi u})du \\
\lambda(\Delta)=\frac{1}{\xi}\left[ \Delta-\xi\left( \log{\frac{\xi}{\epsilon'}}+1-\frac{1}{\sqrt{1-\beta^2}} \right) \right]
Φ ( λ ) = π 1 ∫ 0 ∞ e − u ( l o g u + λ ) sin ( π u ) d u λ ( Δ ) = ξ 1 [ Δ − ξ ( log ϵ ′ ξ + 1 − 1 − β 2 1 ) ]
参数定义为(I I I
ξ = 2 π N A E 4 Z 2 ρ ( ∑ Z ) m e c 2 ( ∑ A ) ϵ ′ = I 2 ( 1 − β 2 ) e β 2 2 m e c 2 β 2 \xi=\frac{2\pi N_AE^4Z^2\rho (\sum Z)}{m_ec^2(\sum A)} \\
\epsilon'=\frac{I^2(1-\beta^2)e^{\beta^2}}{2m_ec^2\beta^2}
ξ = m e c 2 ( ∑ A ) 2 π N A E 4 Z 2 ρ ( ∑ Z ) ϵ ′ = 2 m e c 2 β 2 I 2 ( 1 − β 2 ) e β 2
它可以描述粒子的电离能损或能量沉积.
6.5 随机变量小结
可以总结出一个表格:
离散型
连续型
分布律
分布列:p k = P ( X = x k ) p_k=P(X=x_k) p k = P ( X = x k )
密度函数:f ( x ) d x f(x)dx f ( x ) d x
分布函数
F ( x ) = ∑ x i < x P ( X = x i ) F(x)=\sum_{x_i<x}P(X=x_i) F ( x ) = ∑ x i < x P ( X = x i ) F ( x ) = ∫ − ∞ x f ( x ) d x F(x)=\int_{-\infty}^xf(x)dx F ( x ) = ∫ − ∞ x f ( x ) d x
概率
逐点计算
P ( a < X ≤ b ) = F ( b ) − F ( a ) P(a<X\leq b)=F(b)-F(a) P ( a < X ≤ b ) = F ( b ) − F ( a ) P ( X = a ) = 0 P(X=a)=0 P ( X = a ) = 0
分布函数连续性
F ( x ) F(x) F ( x ) F ( x ) F(x) F ( x )
6.6 随机变量的函数分布
在一些试验中,所关心的随机变量往往不能直接测量得到,而是某个直接测量所得随机变量的函数,此时我们会对某些随机变量的函数的分布更感兴趣.
比如,测量圆轴截面的直径D D D A = π D 2 4 A=\frac{\pi D^2}{4} A = 4 π D 2 A = g ( D ) A=g(D) A = g ( D ) g ( ⋅ ) g(\cdot) g ( ⋅ ) D D D g ( D ) g(D) g ( D )
离散型随机变量的函数分布
对于离散性随机变量,定义是直观的.考虑随机变量X X X
P ( X = x i ) = p i , i = 1 , 2 , 3 , . . . P(X=x_i)=p_i,i=1,2,3,...
P ( X = x i ) = p i , i = 1 , 2 , 3 , ...
那么对于Y = g ( X ) Y=g(X) Y = g ( X )
P ( Y = y i ) = ∑ x ∈ g − 1 ( y i ) P ( X = x ) P(Y=y_i)=\sum_{x\in g^{-1}(y_i)}P(X=x)
P ( Y = y i ) = x ∈ g − 1 ( y i ) ∑ P ( X = x )
也就是说,如果g ( x 1 ) = g ( x 2 ) = y 0 g(x_1)=g(x_2)=y_0 g ( x 1 ) = g ( x 2 ) = y 0 Y = y 0 Y=y_0 Y = y 0
例6.3
设随机变量X X X Y = ( X − 1 ) 2 Y=(X-1)^2 Y = ( X − 1 ) 2
X X X -1 0 1 2 p k p_k p k 0.2 0.3 0.1 0.4
(答案略)
连续型随机变量的函数分布
利用上面的结论,我们不难将上述结论推广至X X X X , Y X,Y X , Y F X ( x ) , F Y ( y ) F_X(x),F_Y(y) F X ( x ) , F Y ( y ) f X ( x ) , f Y ( y ) f_X(x),f_Y(y) f X ( x ) , f Y ( y )
F Y ( y ) = ∫ D y f X ( x ) d x , D y = { x ∈ R ∣ g ( x ) ≤ y } F_Y(y)=\int_{D_y} f_X(x)dx,D_y=\{x\in \mathbb{R}|g(x)\leq y\}
F Y ( y ) = ∫ D y f X ( x ) d x , D y = { x ∈ R ∣ g ( x ) ≤ y }
如果映射g g g F X F_X F X g g g g − 1 g^{-1} g − 1
F Y ( y ) = P ( Y ≤ y ) = P ( X ≤ g − 1 ( y ) ) = F X ( g − 1 ( y ) ) F_Y(y)=P(Y\leq y)=P(X\leq g^{-1}(y))=F_X(g^{-1}(y))
F Y ( y ) = P ( Y ≤ y ) = P ( X ≤ g − 1 ( y )) = F X ( g − 1 ( y ))
例6.4
设随机变量X X X
f X ( x ) = { x 8 , 0 < x < 4 0 , 其他 f_X(x)=\begin{cases} \frac{x}{8}\,\,\,\,,0<x<4\\ 0\,\,\,\,,其他\end{cases} f X ( x ) = { 8 x , 0 < x < 4 0 , 其他
求随机变量Y = 2 X + 8 Y=2X+8 Y = 2 X + 8
(答案略)
我们还可以把映射g g g
连续性随机变量函数的概率密度定理:
设随机变量X X X f X ( x ) , − ∞ < x < + ∞ f_X(x),-\infty<x<+\infty f X ( x ) , − ∞ < x < + ∞ g ( x ) g(x) g ( x ) g ′ ( x ) g'(x) g ′ ( x ) Y = g ( X ) Y=g(X) Y = g ( X )
f Y ( y ) = { f X ( g − 1 ( y ) ) ∣ g − 1 ′ ( y ) ∣ , a < y < b 0 , 其他 f_Y(y)=\begin{cases} f_X(g^{-1}(y))|g^{-1}{'}(y)|\,\,\,\,,a<y<b\\ 0\,\,\,\,,其他 \end{cases} f Y ( y ) = { f X ( g − 1 ( y )) ∣ g − 1 ′ ( y ) ∣ , a < y < b 0 , 其他
证明:
将上文中分布函数形式的定理求导即可得到.注意绝对值!
另一个直观的推导方法是利用f X ( x ) ∣ d x ∣ = f Y ( y ) ∣ d y ∣ f_X(x)|dx|=f_Y(y)|dy| f X ( x ) ∣ d x ∣ = f Y ( y ) ∣ d y ∣
理论介绍完毕,下面给出几个例题:
例6.5 (正态分布伸缩平移)
设随机变量X ∼ N ( μ , σ 2 ) X\sim N(\mu,\sigma^2) X ∼ N ( μ , σ 2 ) Y = a X + b ∼ N ( a μ + b , ( a σ ) 2 ) Y=aX+b\sim N(a\mu+b,(a\sigma)^2) Y = a X + b ∼ N ( a μ + b , ( aσ ) 2 ) a ≠ 0 a\neq 0 a = 0
(答案略,带公式即可)
例6.6 (柯西分布的构造)
设随机变量X ∼ U ( − π / 2 , π / 2 ) X\sim U(-\pi/2,\pi/2) X ∼ U ( − π /2 , π /2 ) Y = tan ( X ) Y=\tan(X) Y = tan ( X )
(答案略,带公式即可)
上题中我们从均匀分布推出了柯西分布.实际上,均匀分布的可延展性比这还要强:它可以通过复合函数构造任意分布!
例6.6 (均匀分布的构造)
若随机变量X X X F X ( x ) F_X(x) F X ( x ) Y = F X ( X ) ∼ U ( 0 , 1 ) Y=F_X(X)\sim U(0,1) Y = F X ( X ) ∼ U ( 0 , 1 )
证明:
利用映射反函数存在情形的定理即得F Y ( y ) = F X ( F X − 1 ( y ) ) = y , 0 ≤ y ≤ 1 F_Y(y)=F_X(F_X^{-1}(y))=y,0\leq y\leq1 F Y ( y ) = F X ( F X − 1 ( y )) = y , 0 ≤ y ≤ 1 Y = F X ( X ) ∼ U ( 0 , 1 ) Y=F_X(X)\sim U(0,1) Y = F X ( X ) ∼ U ( 0 , 1 )
上述过程逆过来即:可以用均匀分布生成任意连续分布.
例6.7 (反函数不存在的情形)
设随机变量X X X f X ( x ) , − ∞ < x < + ∞ f_X(x),-\infty<x<+\infty f X ( x ) , − ∞ < x < + ∞ Y = X 2 Y=X^2 Y = X 2
解:
利用原始形式的概率密度定理即可:
F Y ( y ) = P ( Y ≤ y ) = P ( − y ≤ X ≤ y ) = F X ( y ) − F X ( − y ) F_Y(y)=P(Y\leq y)=P(-\sqrt{y}\leq X\leq\sqrt{y})=F_X(\sqrt{y})-F_X(-\sqrt{y}) F Y ( y ) = P ( Y ≤ y ) = P ( − y ≤ X ≤ y ) = F X ( y ) − F X ( − y )
求导得到:
f Y ( y ) = { 1 2 y [ f X ( y ) + f X ( − y ) ] , y > 0 0 , y ≤ 0 f_Y(y)=\begin{cases} \frac{1}{2\sqrt{y}}[f_X(\sqrt{y})+f_X(-\sqrt{y})]\,\,\,\,,y>0\\ \\ 0\,\,\,\,,y\leq 0\end{cases} f Y ( y ) = ⎩ ⎨ ⎧ 2 y 1 [ f X ( y ) + f X ( − y )] , y > 0 0 , y ≤ 0
不难发现,带入X ∼ N ( 0 , 1 ) X\sim N(0,1) X ∼ N ( 0 , 1 ) f X ( x ) = 1 2 π e − x 2 2 f_X(x)=\frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}} f X ( x ) = 2 π 1 e − 2 x 2 f Y ( y ) = 1 2 π y e − y 2 , y > 0 f_Y(y)=\frac{1}{\sqrt{2\pi y}}e^{-\frac{y}{2}},y>0 f Y ( y ) = 2 π y 1 e − 2 y , y > 0 Y ∼ χ 2 ( 1 ) Y\sim \chi^2(1) Y ∼ χ 2 ( 1 )
L7 二维随机变量
(待补)
L8 二维随机变量函数
8.1 二维正态分布
我们通常能通过一些一维分布的拼贴构造出一些二元分布(比如上节课的泊松+二项=新的泊松),而教材中唯一特别讨论的二维分布就是二维正态分布.
考虑X ∼ N ( μ 1 , σ 1 2 ) , Y ∼ N ( μ 2 , σ 2 2 ) X\sim N(\mu_1,\sigma_1^2),Y\sim N(\mu_2,\sigma_2^2) X ∼ N ( μ 1 , σ 1 2 ) , Y ∼ N ( μ 2 , σ 2 2 )
⟹ f X ( x ) = 1 2 π σ 1 exp [ − ( x − μ 1 ) 2 2 σ 1 2 ] f Y ( y ) = 1 2 π σ 2 exp [ − ( y − μ 2 ) 2 2 σ 2 2 ] ⟹ f ( x , y ) = f X ( x ) f Y ( y ) = 1 2 π σ 1 σ 2 exp [ − ( x − μ 1 ) 2 2 σ 1 2 − ( y − μ 2 ) 2 2 σ 2 2 ] \begin{aligned}
\Longrightarrow &f_X(x)=\frac{1}{\sqrt{2\pi}\sigma_1}\exp\left[
-\frac{(x-\mu_1)^2}{2\sigma_1^2}
\right]\\
&f_Y(y)=\frac{1}{\sqrt{2\pi}\sigma_2}\exp\left[
-\frac{(y-\mu_2)^2}{2\sigma_2^2}
\right]\\
\Longrightarrow &f(x,y)=f_X(x)f_Y(y)=\frac{1}{2\pi\sigma_1\sigma_2}\exp\left[
-\frac{(x-\mu_1)^2}{2\sigma_1^2}-\frac{(y-\mu_2)^2}{2\sigma_2^2}
\right]
\end{aligned}
⟹ ⟹ f X ( x ) = 2 π σ 1 1 exp [ − 2 σ 1 2 ( x − μ 1 ) 2 ] f Y ( y ) = 2 π σ 2 1 exp [ − 2 σ 2 2 ( y − μ 2 ) 2 ] f ( x , y ) = f X ( x ) f Y ( y ) = 2 π σ 1 σ 2 1 exp [ − 2 σ 1 2 ( x − μ 1 ) 2 − 2 σ 2 2 ( y − μ 2 ) 2 ]
于是拓展后我们得到如下定义:
二维正态分布的定义
f ( x , y ) = 1 2 π σ 1 σ 2 1 − ρ 2 e − 1 2 ( 1 − ρ 2 ) [ ( x − μ 1 ) 2 σ 1 2 − 2 ρ ( x − μ 1 ) ( y − μ 2 ) σ 1 σ 2 + ( y − μ 2 ) 2 σ 2 2 ] f(x,y)=\frac{1}{2\pi\sigma_1\sigma_2\sqrt{1-\rho^2}}e^{-\frac{1}{2(1-\rho^2)}\left[\frac{(x-\mu_1)^2}{\sigma_1^2}-2\rho\frac{(x-\mu_1)(y-\mu_2)}{\sigma_1\sigma_2}+\frac{(y-\mu_2)^2}{\sigma_2^2}\right]} f ( x , y ) = 2 π σ 1 σ 2 1 − ρ 2 1 e − 2 ( 1 − ρ 2 ) 1 [ σ 1 2 ( x − μ 1 ) 2 − 2 ρ σ 1 σ 2 ( x − μ 1 ) ( y − μ 2 ) + σ 2 2 ( y − μ 2 ) 2 ]
具有以上概率密度函数的分布称为二维正态分布 .
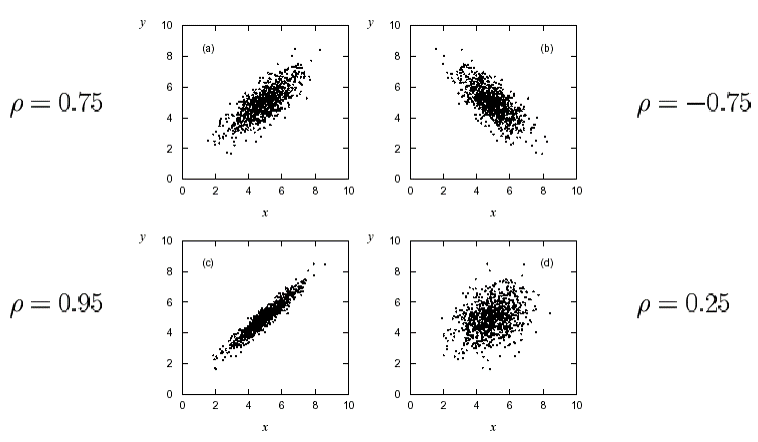
以上为二维正态分布的标准形式,其中能体现出一些与我们的直觉相关的特征量.记作:( X , Y ) ∼ N ( μ 1 , σ 1 2 ; μ 2 , σ 2 2 ; ρ ) (X,Y)\sim N(\mu_1,\sigma_1^2;\mu_2,\sigma_2^2;\rho) ( X , Y ) ∼ N ( μ 1 , σ 1 2 ; μ 2 , σ 2 2 ; ρ )
特征量的含义
( X , Y ) ∼ N ( μ 1 , σ 1 2 ; μ 2 , σ 2 2 ; ρ ) (X,Y)\sim N(\mu_1,\sigma_1^2;\mu_2,\sigma_2^2;\rho)
( X , Y ) ∼ N ( μ 1 , σ 1 2 ; μ 2 , σ 2 2 ; ρ )
容易证明,X , Y X,Y X , Y ρ = 0 \rho=0 ρ = 0
证明思路: x = μ 1 , y = μ 2 x=\mu_1,y=\mu_2 x = μ 1 , y = μ 2 1 1 − ρ 2 = 1 \frac{1}{\sqrt{1-\rho^2}}=1 1 − ρ 2 1 = 1
思考题: (选做,总评+2%)
ρ = ± 1 \rho = \pm 1 ρ = ± 1 N ( μ 1 , σ 1 2 ; μ 2 , σ 2 2 ; ρ ) N(\mu_1,\sigma_1^2;\mu_2,\sigma_2^2;\rho) N ( μ 1 , σ 1 2 ; μ 2 , σ 2 2 ; ρ )
多维伽马分布调研作业(选做,总评至多+15%)
二维正态分布是最常用的多维随机变量分布.但当我们想考虑全部为正实数的随机变量时,更常用的是多维伽马分布,Multivariate Gamma Distribution .
f ( z ) = ∣ Σ − 1 ∣ α ∣ z ∣ α − 1 / 2 ( p + 1 ) β p α Γ p ( α ) exp [ − 1 β t r Σ − 1 z ] f(\bm{z})=\frac{|\Sigma^{-1}|^\alpha|\bm{z}|^{\alpha-1/2(p+1)}}{\beta^{p\alpha}\Gamma_p(\alpha)}\exp\left[ -\frac{1}{\beta} \mathrm{tr}\Sigma^{-1}\bm{z}\right]
f ( z ) = β p α Γ p ( α ) ∣ Σ − 1 ∣ α ∣ z ∣ α − 1/2 ( p + 1 ) exp [ − β 1 tr Σ − 1 z ]
调研任务
①自行寻找相关教材或论文,可以请教老师和助教.
②调研文献中各类型的多维伽马分布定义,阐释其联系与区别.
③调研多维伽马分布中参数的含义.
④调研多维伽马分布的应用实例.
⑤学习使用LaTeX \LaTeX L A T E X
8.2 随机变量函数的分布
类似一维随机变量的函数,多个随机变量的函数同样重要.
譬如,对两个随机变量的函数,我们的目标如下:
假设( X , Y ) (X,Y) ( X , Y ) f ( x , y ) f(x,y) f ( x , y ) Z = g ( X , Y ) Z=g(X,Y) Z = g ( X , Y )
常见的g ( X , Y ) g(X,Y) g ( X , Y ) X ± Y , Y / X , X Y , max { X , Y } , min { X , Y } X \pm Y,Y/X,XY,\max\{X,Y\},\min\{X,Y\} X ± Y , Y / X , X Y , max { X , Y } , min { X , Y }
一般情形下的变换
多维情形的概率密度定理:
如果函数u = g 1 ( x , y ) , v = g 2 ( x , y ) u=g_1(x,y),v=g_2(x,y) u = g 1 ( x , y ) , v = g 2 ( x , y )
{ x = x ( u , v ) y = y ( u , v ) \begin{cases} x=x(u,v)\\ y=y(u,v)\end{cases} { x = x ( u , v ) y = y ( u , v )
该变换的雅可比行列式
J = ∂ ( x , y ) ∂ ( u , v ) = ∣ ∂ x ∂ u ∂ y ∂ u ∂ x ∂ v ∂ y ∂ v ∣ J=\frac{\partial (x,y)}{\partial(u,v)}=\begin{vmatrix} \frac{\partial x}{\partial u} & \frac{\partial y}{\partial u} \\ \frac{\partial x}{\partial v} & \frac{\partial y}{\partial v} \end{vmatrix} J = ∂ ( u , v ) ∂ ( x , y ) = ∂ u ∂ x ∂ v ∂ x ∂ u ∂ y ∂ v ∂ y
则随机变量U = g 1 ( X , Y ) , V = g 2 ( X , Y ) U=g_1(X,Y),V=g_2(X,Y) U = g 1 ( X , Y ) , V = g 2 ( X , Y )
g ( u , v ) = f [ x ( u , v ) , y ( u , v ) ] ∣ J ∣ g(u,v)=f[x(u,v),y(u,v)]|J| g ( u , v ) = f [ x ( u , v ) , y ( u , v )] ∣ J ∣
注意这里的双竖线∣ J ∣ |J| ∣ J ∣
下面用极坐标下的二维正态分布为例.
例8.1 (极坐标)
假设x , y x,y x , y N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) ( ρ , ϕ ) (\rho,\phi) ( ρ , ϕ )
ρ = x 2 + y 2 , ρ > 0 ϕ = tan − 1 ( y x ) , ϕ ∈ [ 0 , 2 π ] \begin{aligned} &\rho=\sqrt{x^2+y^2} , &\rho>0\\ &\phi=\tan^{-1}\left( \frac{y}{x} \right) , &\phi\in[0,2\pi]\end{aligned} ρ = x 2 + y 2 , ϕ = tan − 1 ( x y ) , ρ > 0 ϕ ∈ [ 0 , 2 π ]
并求( ρ , ϕ ) (\rho,\phi) ( ρ , ϕ )
>
解:
考虑到x = ρ cos ϕ , y = ρ sin ϕ x=\rho \cos\phi,y=\rho \sin\phi x = ρ cos ϕ , y = ρ sin ϕ
J = ∣ ∂ x ∂ ρ ∂ y ∂ ρ ∂ x ∂ ϕ ∂ y ∂ ϕ ∣ = ∣ cos ϕ sin ϕ − ρ sin ϕ ρ cos ϕ ∣ = ρ J=\begin{vmatrix} \frac{\partial x}{\partial \rho} & \frac{\partial y}{\partial \rho} \\ \frac{\partial x}{\partial \phi} & \frac{\partial y}{\partial \phi} \end{vmatrix}=\begin{vmatrix} \cos\phi & \sin\phi \\ -\rho\sin\phi & \rho\cos\phi \end{vmatrix}=\rho J = ∂ ρ ∂ x ∂ ϕ ∂ x ∂ ρ ∂ y ∂ ϕ ∂ y = cos ϕ − ρ sin ϕ sin ϕ ρ cos ϕ = ρ
于是乎:
g ( ρ , ϕ ) = f ( x , y ) ∣ J ∣ = 1 2 π e − ( ρ cos ϕ ) 2 2 ⋅ 1 2 π e − ( ρ sin ϕ ) 2 2 ⋅ ρ = 1 2 π ρ e − ρ 2 2 , ρ ≥ 0 \begin{aligned} g(\rho,\phi) &=f(x,y)|J|\\ &=\frac{1}{\sqrt{2\pi}}e^{-\frac{(\rho\cos\phi)^2}{2}}\cdot\frac{1}{\sqrt{2\pi}}e^{-\frac{(\rho\sin\phi)^2}{2}}\cdot\rho \\ &=\frac{1}{2\pi}\rho e^{-\frac{\rho^2}{2}},\rho\geq 0\end{aligned} g ( ρ , ϕ ) = f ( x , y ) ∣ J ∣ = 2 π 1 e − 2 ( ρ c o s ϕ ) 2 ⋅ 2 π 1 e − 2 ( ρ s i n ϕ ) 2 ⋅ ρ = 2 π 1 ρ e − 2 ρ 2 , ρ ≥ 0
此为关于ρ \rho ρ 瑞利分布 (是的,你也会在瑞利散射中看到这个函数).
联合密度函数与ϕ \phi ϕ ρ , ϕ \rho,\phi ρ , ϕ ϕ \phi ϕ f Φ ( ϕ ) = 1 2 π , ϕ ∈ [ 0 , 2 π ] f_{\Phi}(\phi)=\frac{1}{2\pi},\phi \in [0,2\pi] f Φ ( ϕ ) = 2 π 1 , ϕ ∈ [ 0 , 2 π ]
增补变量法
回到我们的原始问题:假设( X , Y ) (X,Y) ( X , Y ) f ( x , y ) f(x,y) f ( x , y ) U = g ( X , Y ) U=g(X,Y) U = g ( X , Y )
两个变量合并成一个函数变量,我们常常用增补变量法 求解,简单过程图如下:
( X , Y ) ⟶ 函数变换 ( g ( X , Y ) , X ) ⟶ 边缘分布 g ( X , Y ) (X,Y)\stackrel{函数变换}{\longrightarrow}(g(X,Y),X)\stackrel{边缘分布}{\longrightarrow}g(X,Y) ( X , Y ) ⟶ 函数变换 ( g ( X , Y ) , X ) ⟶ 边缘分布 g ( X , Y )
增补新变量V = X V=X V = X V = Y V=Y V = Y 用变换法求( U , V ) (U,V) ( U , V ) g ( u , v ) g(u,v) g ( u , v ) 关于v v v U = g ( X , Y ) U=g(X,Y) U = g ( X , Y )
以下我们要讨论的函数都可以用这一方法求解.
8.3 X + Y X+Y X + Y
这是今天最最重要的一种函数,它还有一些fancy的别名:“卷积”、"探测器响应"等.
傅里叶卷积:
假设( X , Y ) (X,Y) ( X , Y ) f ( x , y ) , − ∞ < x , y < + ∞ f(x,y),-\infty<x,y<+\infty f ( x , y ) , − ∞ < x , y < + ∞ Z = X + Y Z=X+Y Z = X + Y
f X + Y ( z ) = ∫ − ∞ + ∞ f ( z − y , y ) d y = ∫ − ∞ + ∞ f ( x , z − x ) d x f_{X+Y}(z)=\int_{-\infty}^{+\infty}f(z-y,y)dy=\int_{-\infty}^{+\infty}f(x,z-x)dx f X + Y ( z ) = ∫ − ∞ + ∞ f ( z − y , y ) d y = ∫ − ∞ + ∞ f ( x , z − x ) d x
若X , Y X,Y X , Y f X ( x ) , f Y ( y ) f_X(x),f_Y(y) f X ( x ) , f Y ( y )
f X + Y ( z ) = ∫ − ∞ + ∞ f X ( z − y ) f Y ( y ) d y = ∫ − ∞ + ∞ f X ( x ) f Y ( z − x ) d x f_{X+Y}(z)=\int_{-\infty}^{+\infty}f_X(z-y)f_Y(y)dy=\int_{-\infty}^{+\infty}f_X(x)f_Y(z-x)dx f X + Y ( z ) = ∫ − ∞ + ∞ f X ( z − y ) f Y ( y ) d y = ∫ − ∞ + ∞ f X ( x ) f Y ( z − x ) d x
这被称为f X , f Y f_X,f_Y f X , f Y 傅里叶卷积公式 ,记为f X ∗ f Y f_X * f_Y f X ∗ f Y
证明:
考虑随机变量Z Z Z F Z ( z ) F_Z(z) F Z ( z )
F Z ( z ) = ∬ x + y ≤ z f ( x , y ) d x d y = ∫ − ∞ + ∞ ∫ − ∞ z − y f ( x , y ) d x d y \begin{aligned} F_Z(z)&=\iint_{x+y\leq z}f(x,y)dxdy\\ &=\int_{-\infty}^{+\infty}\int_{-\infty}^{z-y}f(x,y)dxdy\end{aligned} F Z ( z ) = ∬ x + y ≤ z f ( x , y ) d x d y = ∫ − ∞ + ∞ ∫ − ∞ z − y f ( x , y ) d x d y
做变量替换:( x , y ) → ( u , y ) = ( x + y , y ) (x,y)\rightarrow(u,y)=(x+y,y) ( x , y ) → ( u , y ) = ( x + y , y )
F Z ( z ) = ∫ − ∞ + ∞ ∫ − ∞ z f ( u − y , y ) d u d y = ∫ − ∞ z [ ∫ − ∞ + ∞ f ( u − y , y ) d y ] d u ⟹ f X + Y ( z ) = F Z ′ ( z ) = ∫ − ∞ + ∞ f ( z − y , y ) d y \begin{aligned} F_Z(z)&=\int_{-\infty}^{+\infty}\int_{-\infty}^{z}f(u-y,y)dudy\\ &=\int_{-\infty}^{z}\left[\int_{-\infty}^{+\infty}f(u-y,y)dy\right]du\\ \Longrightarrow f_{X+Y}(z)&=F'_Z(z)=\int_{-\infty}^{+\infty}f(z-y,y)dy\end{aligned} F Z ( z ) ⟹ f X + Y ( z ) = ∫ − ∞ + ∞ ∫ − ∞ z f ( u − y , y ) d u d y = ∫ − ∞ z [ ∫ − ∞ + ∞ f ( u − y , y ) d y ] d u = F Z ′ ( z ) = ∫ − ∞ + ∞ f ( z − y , y ) d y
证毕.
我们还有另一种利用微分形式与边缘分布的证明:我们知道微分形式有d x ∧ d y = − d y ∧ d x , d x ∧ d x = 0 dx\wedge dy=-dy\wedge dx,dx\wedge dx=0 d x ∧ d y = − d y ∧ d x , d x ∧ d x = 0
f ( x , y ) d x d y = f ( z − y , y ) d ( z − y ) d y = f ( z − y , y ) ( d z ∧ d y − d y ∧ d y ) = f ( z − y , y ) d z d y \begin{aligned} f(x,y)dxdy&=f(z-y,y)d(z-y)dy\\ &=f(z-y,y)(dz\wedge dy-dy\wedge dy)\\ &=f(z-y,y)dzdy\end{aligned} f ( x , y ) d x d y = f ( z − y , y ) d ( z − y ) d y = f ( z − y , y ) ( d z ∧ d y − d y ∧ d y ) = f ( z − y , y ) d z d y
于是Z Z Z
f Z ( z ) d z = [ ∫ − ∞ + ∞ f ( z − y , y ) d y ] d z f_Z(z)dz=\left[ \int_{-\infty}^{+\infty}f(z-y,y)dy \right] dz f Z ( z ) d z = [ ∫ − ∞ + ∞ f ( z − y , y ) d y ] d z
同样得证,这个证明方法是严格的.
可以看到,通常简单的加法运算在随机变量的概率密度上可以等价映射为一个复杂的积分操作,还挺神奇的.反过来,一些复杂的积分也可以通过随机变量的简单运算来刻画,这方面会在学期最后一课介绍.
例8.2 (高斯分布可加)
设X , Y X,Y X , Y N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) Z = X + Y Z=X+Y Z = X + Y
解:
容易写出:
f X + Y ( z ) = 1 2 π ∫ − ∞ + ∞ e − ( z − y ) 2 2 e − y 2 2 d y = 1 2 π e − z 2 4 ∫ − ∞ + ∞ e − ( y − 1 2 z ) 2 d y = 1 2 π e − z 2 4 \begin{aligned} f_{X+Y}(z)&=\frac{1}{2\pi}\int_{-\infty}^{+\infty}e^{-\frac{(z-y)^2}{2}}e^{-\frac{y^2}{2}}dy\\ &=\frac{1}{2\pi}e^{-\frac{z^2}{4}}\int_{-\infty}^{+\infty}e^{-(y-\frac{1}{2}z)^2}dy \\ &= \frac{1}{2\sqrt{\pi}}e^{-\frac{z^2}{4}}\end{aligned} f X + Y ( z ) = 2 π 1 ∫ − ∞ + ∞ e − 2 ( z − y ) 2 e − 2 y 2 d y = 2 π 1 e − 4 z 2 ∫ − ∞ + ∞ e − ( y − 2 1 z ) 2 d y = 2 π 1 e − 4 z 2
服从N ( 0 , 2 ) N(0,2) N ( 0 , 2 )
类似的高斯不变现象还有很多,比如:
若X , Y X,Y X , Y X ∼ N ( μ 1 , σ 1 2 ) , Y ∼ N ( μ 1 , σ 1 2 ) X\sim N(\mu_1,\sigma_1^2),Y\sim N(\mu_1,\sigma_1^2) X ∼ N ( μ 1 , σ 1 2 ) , Y ∼ N ( μ 1 , σ 1 2 ) X + Y ∼ N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 ) X+Y\sim N(\mu_1+\mu_2,\sigma_1^2+\sigma_2^2) X + Y ∼ N ( μ 1 + μ 2 , σ 1 2 + σ 2 2 ) 边缘分布:若( X , Y ) ∼ N ( μ 1 , σ 1 2 ; μ 2 , σ 2 2 ; ρ ) (X,Y)\sim N(\mu_1,\sigma_1^2;\mu_2,\sigma_2^2;\rho) ( X , Y ) ∼ N ( μ 1 , σ 1 2 ; μ 2 , σ 2 2 ; ρ ) X ∼ N ( μ 1 , σ 1 2 ) , Y ∼ N ( μ 1 , σ 1 2 ) X\sim N(\mu_1,\sigma_1^2),Y\sim N(\mu_1,\sigma_1^2) X ∼ N ( μ 1 , σ 1 2 ) , Y ∼ N ( μ 1 , σ 1 2 )
条件分布:若( X , Y ) ∼ N ( μ 1 , σ 1 2 ; μ 2 , σ 2 2 ; ρ ) (X,Y)\sim N(\mu_1,\sigma_1^2;\mu_2,\sigma_2^2;\rho) ( X , Y ) ∼ N ( μ 1 , σ 1 2 ; μ 2 , σ 2 2 ; ρ ) X ∣ Y ∼ N ( μ 1 − ( Y − μ 2 ) ρ σ 1 σ 2 , ( 1 − ρ 2 ) σ 1 2 ) Y ∣ X ∼ N ( μ 2 − ( Y − μ 1 ) ρ σ 2 σ 1 , ( 1 − ρ 2 ) σ 2 2 ) X|Y\sim N\left(\mu_1-(Y-\mu_2)\rho\frac{\sigma_1}{\sigma_2},(1-\rho^2)\sigma_1^2\right) \\ Y|X\sim N\left(\mu_2-(Y-\mu_1)\rho\frac{\sigma_2}{\sigma_1},(1-\rho^2)\sigma_2^2\right) X ∣ Y ∼ N ( μ 1 − ( Y − μ 2 ) ρ σ 2 σ 1 , ( 1 − ρ 2 ) σ 1 2 ) Y ∣ X ∼ N ( μ 2 − ( Y − μ 1 ) ρ σ 1 σ 2 , ( 1 − ρ 2 ) σ 2 2 )
例8.3 (指数分布)
X ∼ E x p ( λ ) , Y ∼ E x p ( λ ) X\sim Exp(\lambda),Y\sim Exp(\lambda) X ∼ E x p ( λ ) , Y ∼ E x p ( λ )
那么X + Y X+Y X + Y
解:
f X + Y ( z ) = ∫ 0 z λ e − λ z λ e − λ ( z − x ) d x = λ 2 ∫ 0 z e − λ ( z ) d x = λ 2 z e − λ z \begin{aligned} f_{X+Y}(z)&=\int_0^z \lambda e^{-\lambda z}\lambda e^{-\lambda(z-x)}dx\\ &=\lambda^2\int_0^ze^{-\lambda(z)}dx\\ &=\lambda^2ze^{-\lambda z}\end{aligned} f X + Y ( z ) = ∫ 0 z λ e − λ z λ e − λ ( z − x ) d x = λ 2 ∫ 0 z e − λ ( z ) d x = λ 2 z e − λ z
服从G a ( 2 , λ ) Ga(2,\lambda) G a ( 2 , λ )
8.4 Y / X , X Y Y/X,XY Y / X , X Y
梅林卷积:
假设( X , Y ) (X,Y) ( X , Y ) f ( x , y ) , − ∞ < x , y < + ∞ f(x,y),-\infty<x,y<+\infty f ( x , y ) , − ∞ < x , y < + ∞ Y X , X Y \frac{Y}{X},XY X Y , X Y
f Y X ( z ) = ∫ − ∞ + ∞ ∣ x ∣ f ( x , x z ) d x , f X Y ( z ) = ∫ − ∞ + ∞ 1 ∣ x ∣ f ( x , z x ) d x f_{\frac{Y}{X}}(z)=\int_{-\infty}^{+\infty}|x|f(x,xz)dx,f_{XY}(z)=\int_{-\infty}^{+\infty}\frac{1}{|x|}f\left(x,\frac{z}{x}\right)dx f X Y ( z ) = ∫ − ∞ + ∞ ∣ x ∣ f ( x , x z ) d x , f X Y ( z ) = ∫ − ∞ + ∞ ∣ x ∣ 1 f ( x , x z ) d x
若X , Y X,Y X , Y f X ( x ) , f Y ( y ) f_X(x),f_Y(y) f X ( x ) , f Y ( y )
f Y X ( z ) = ∫ − ∞ + ∞ ∣ x ∣ f X ( x ) f Y ( x z ) d x , f X Y ( z ) = ∫ − ∞ + ∞ 1 ∣ x ∣ f X ( x ) f Y ( z x ) d x f_{\frac{Y}{X}}(z)=\int_{-\infty}^{+\infty}|x|f_X(x)f_Y(xz)dx,f_{XY}(z)=\int_{-\infty}^{+\infty}\frac{1}{|x|}f_X(x)f_Y\left(\frac{z}{x}\right)dx f X Y ( z ) = ∫ − ∞ + ∞ ∣ x ∣ f X ( x ) f Y ( x z ) d x , f X Y ( z ) = ∫ − ∞ + ∞ ∣ x ∣ 1 f X ( x ) f Y ( x z ) d x
第二个公式被称为f X , f Y f_X,f_Y f X , f Y 梅林(Mellin)卷积公式
证明过程和傅里叶卷积的方法类似,仍然用增补变量法,此处略去.值得一提的是,教材中用线画区域证明,用了一页半的篇幅.(…)
例8.4 (高斯翻车变柯西)
设X , Y X,Y X , Y N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) Z = Y X Z=\frac{Y}{X} Z = X Y
解: ( X , Y ) (X,Y) ( X , Y ) f ( x , y ) = 1 2 π e − x 2 + y 2 2 , − ∞ < x , y < + ∞ f(x,y)=\frac{1}{2\pi}e^{-\frac{x^2+y^2}{2}},-\infty<x,y<+\infty f ( x , y ) = 2 π 1 e − 2 x 2 + y 2 , − ∞ < x , y < + ∞
f Y X ( z ) = ∫ − ∞ + ∞ ∣ x ∣ f ( x , z x ) d x = 1 2 π ∫ − ∞ + ∞ ∣ x ∣ e − x 2 ( 1 + z 2 ) 2 d x = 1 π ∫ 0 + ∞ x e − x 2 ( 1 + z 2 ) 2 d x = 1 π ( 1 + z 2 ) \begin{aligned} f_{\frac{Y}{X}}(z)&=\int_{-\infty}^{+\infty}|x|f(x,zx)dx\\ &=\frac{1}{2\pi}\int_{-\infty}^{+\infty}|x|e^{-\frac{x^2(1+z^2)}{2}}dx\\ &=\frac{1}{\pi}\int_{0}^{+\infty}xe^{-\frac{x^2(1+z^2)}{2}}dx\\ &=\frac{1}{\pi(1+z^2)}\end{aligned} f X Y ( z ) = ∫ − ∞ + ∞ ∣ x ∣ f ( x , z x ) d x = 2 π 1 ∫ − ∞ + ∞ ∣ x ∣ e − 2 x 2 ( 1 + z 2 ) d x = π 1 ∫ 0 + ∞ x e − 2 x 2 ( 1 + z 2 ) d x = π ( 1 + z 2 ) 1
是一个典型的柯西分布.
8.5 min { X , Y } \min\{X,Y\} min { X , Y } max { X , Y } \max\{X,Y\} max { X , Y }
假设( X , Y ) (X,Y) ( X , Y ) F X ( x ) , F Y ( y ) F_X(x),F_Y(y) F X ( x ) , F Y ( y ) max ( X , Y ) , min ( X , Y ) \max(X,Y),\min(X,Y) max ( X , Y ) , min ( X , Y )
F max ( z ) = F X ( z ) F Y ( z ) , F min ( z ) = 1 − [ 1 − F X ( z ) ] [ 1 − F Y ( z ) ] F_{\max}(z)=F_X(z)F_Y(z),F_{\min}(z)=1-[1-F_X(z)][1-F_Y(z)]
F m a x ( z ) = F X ( z ) F Y ( z ) , F m i n ( z ) = 1 − [ 1 − F X ( z )] [ 1 − F Y ( z )]
进一步地若X , Y X,Y X , Y
F max ( z ) = [ F ( z ) ] 2 , F min ( z ) = 1 − [ 1 − F ( z ) ] 2 F_{\max}(z)=[F(z)]^2,F_{\min}(z)=1-[1-F(z)]^2
F m a x ( z ) = [ F ( z ) ] 2 , F m i n ( z ) = 1 − [ 1 − F ( z ) ] 2
证明:
F max ( z ) = P ( ( X ≤ z ) ∧ ( Y ≤ z ) ) = P ( X ≤ z ) P ( Y ≤ z ) = F X ( z ) F Y ( z ) F min ( z ) = P ( ( X ≤ z ) ∨ ( Y ≤ z ) ) = 1 − P ( ( X ≠ z ) ∧ ( Y ≠ z ) ) = 1 − [ 1 − F X ( z ) ] [ 1 − F Y ( z ) ] F_{\max}(z)=P((X\leq z)\wedge(Y\leq z))=P(X\leq z)P(Y\leq z)=F_X(z)F_Y(z)\\F_{\min}(z)=P((X\leq z)\vee(Y\leq z))=1-P((X\neq z)\wedge(Y\neq z))=1-[1-F_X(z)][1-F_Y(z)] F m a x ( z ) = P (( X ≤ z ) ∧ ( Y ≤ z )) = P ( X ≤ z ) P ( Y ≤ z ) = F X ( z ) F Y ( z ) F m i n ( z ) = P (( X ≤ z ) ∨ ( Y ≤ z )) = 1 − P (( X = z ) ∧ ( Y = z )) = 1 − [ 1 − F X ( z )] [ 1 − F Y ( z )]
证毕.
接下来是一个比较难(?)的例题(考场上1/60正确率说是),但其实就是本节情况的基础练习.
例8.5 (竞争的指数分布)
有两名助教在教室中给同学一对一答疑,每次答疑用时t ∼ E x p ( λ ) t\sim Exp(\lambda) t ∼ E x p ( λ ) t 0 t_0 t 0
解:
由于两助教答疑时间T 1 , T 2 T_1,T_2 T 1 , T 2 E x p ( λ ) Exp(\lambda) E x p ( λ )
T 0 = min ( T 1 , T 2 ) ∼ E x p ( 2 λ ) T_0=\min(T_1,T_2)\sim Exp(2\lambda) T 0 = min ( T 1 , T 2 ) ∼ E x p ( 2 λ )
L9 数学期望
分布函数已经能完整描述随机变量的统计特征了,然而它是函数,较复杂,实际应用中希望用数字对随机变量进行概括,称为这个随机变量的数字特征 .
例9.1
课程的考试中,比起每个学生的具体成绩,教务处更关心平均分和特高分、特低分比例.教务总希望平均分不高不低,不及格、特高分不要太多.
这些数字特征虽然不能完整描述这个随机变量,但它们能描述随机变量某些方面的特征,具有重要的意义.
常见的数字特征有:
数学期望 :随机变量平均取值;方差 :随机变量取值偏离均值程度;协方差、相关系数 :不同随机变量之间的某种关系.
9.1 数学期望
数学期望定义
首先给出数学期望的定义(我们这里只讨论离散型、连续型)
数学期望定义:
离散型
设X X X P ( X = x k ) = p k , k = 1 , 2 , ⋯ P(X=x_k)=p_k,k=1,2,\cdots P ( X = x k ) = p k , k = 1 , 2 , ⋯ ∑ k = 1 + ∞ x k p k \sum_{k=1}^{+\infty}x_kp_k ∑ k = 1 + ∞ x k p k X X X 数学期望 即为该级数,记作E ( X ) \mathrm{E}(X) E ( X )
E ( X ) = ∑ k = 1 + ∞ x k p k \mathrm{E}(X)=\sum_{k=1}^{+\infty}x_kp_k E ( X ) = k = 1 ∑ + ∞ x k p k
连续型
设X X X f ( x ) f(x) f ( x ) ∫ − ∞ + ∞ x f ( x ) d x \int_{-\infty}^{+\infty}xf(x)dx ∫ − ∞ + ∞ x f ( x ) d x X X X 数学期望 即为该积分,记作E ( X ) \mathrm{E}(X) E ( X )
E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x = ∫ − ∞ + ∞ x d ( F ( x ) ) \mathrm{E}(X)=\int_{-\infty}^{+\infty}xf(x)dx=\int_{-\infty}^{+\infty}xd(F(x)) E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x = ∫ − ∞ + ∞ x d ( F ( x ))
实际上,引入了分布函数F ( x ) F(x) F ( x )
关于数学期望的一些要点:
数学期望的本质是"加权平均",概率即权重; 数学期望E ( X ) \mathrm{E}(X) E ( X ) E [ X ] \mathrm{E}[X] E [ X ] 对于给定分布的随机变量,数学期望是一个数,而非随机变量;
是否能将数学期望E \mathrm{E} E
例9.2 (良心卖家)
某商家对某电器的销售采用先试用后付款,记使用寿命为X X X
X ≤ 1 一台 1500 元 1 < X ≤ 2 一台 2000 元 2 < X ≤ 3 一台 2500 元 X > 3 一台 3000 元 \begin{aligned} &X\leq 1 &一台1500元\\ &1<X\leq 2 &一台2000元\\ &2<X\leq 3 &一台2500元\\ &X> 3 &一台3000元\end{aligned} X ≤ 1 1 < X ≤ 2 2 < X ≤ 3 X > 3 一台 1500 元 一台 2000 元 一台 2500 元 一台 3000 元
设寿命X X X
f ( x ) = { 1 10 e − x 10 , x > 0 0 , x ≤ 0 f(x)=\begin{cases} \frac{1}{10}e^{-\frac{x}{10}} , &x>0\\ 0,&x\leq 0\end{cases} f ( x ) = { 10 1 e − 10 x , 0 , x > 0 x ≤ 0
求该商店每台家用电器收费Y Y Y
解题思路:
注意到Y Y Y X X X X X X F X ( x ) = 1 − e − x 10 , x > 0 F_X(x)=1-e^{-\frac{x}{10}},x>0 F X ( x ) = 1 − e − 10 x , x > 0
答案: E ( Y ) = 2732.15 \mathrm{E}(Y)=2732.15 E ( Y ) = 2732.15
例9.3 (赌场停电)
技能相当的两人各出50元对赌,五局三胜,甲胜2局乙胜1局时停电了,停止游戏,赌注如何归还?
解: X X X X = 100 X=100 X = 100 X = 0 X=0 X = 0
P ( X = 100 ) = 3 4 P ( X = 0 ) = 1 4 P(X=100)=\frac{3}{4}\\P(X=0)=\frac{1}{4} P ( X = 100 ) = 4 3 P ( X = 0 ) = 4 1
于是E ( X ) = 75 \mathrm{E}(X)=75 E ( X ) = 75
本例虽然简单,但其实是"数学期望"这个概念在历史上的起源(为啥平均要叫"期望"呢?这就是原因).
1654年7月29日,法国骑士梅累(Chevalier de Méré,1607——1684,数学史上最神秘の赌鬼)向数学神童帕斯卡(Pascal ,1623——1662)提出了一个使他苦恼很久的问题:"两个赌徒相约若干局,谁先赢了a ( a < s ) a(a < s) a ( a < s ) b ( b < s ) b(b<s) b ( b < s )
常见分布的期望
以下表格可自行验算(超几何分布比较麻烦).
离散型随机变量:
分布
概率分布P ( X = k ) P(X=k) P ( X = k )
期望值
01分布
p k ( 1 − p ) k , k = 0 , 1 p^k(1-p)^k,k=0,1 p k ( 1 − p ) k , k = 0 , 1 p \textcolor{blue}{p} p
b ( n , p ) b(n,p) b ( n , p ) ( n k ) p k ( 1 − p ) n − k , k = 0 , 1 , ⋯ , n \begin{pmatrix} n \\ k \end{pmatrix}p^k(1-p)^{n-k},k=0,1,\cdots,n ( n k ) p k ( 1 − p ) n − k , k = 0 , 1 , ⋯ , n n p \textcolor{blue}{np} n p
π ( λ ) \pi(\lambda) π ( λ ) ( λ k / k ! ) e − λ , k = 0 , 1 , 2 , ⋯ (\lambda^k/k!)e^{-\lambda},k=0,1,2,\cdots ( λ k / k !) e − λ , k = 0 , 1 , 2 , ⋯ λ \textcolor{blue}{\lambda} λ
h ( n , M ) h(n,M) h ( n , M ) ( M k ) ( n − k N − M ) / ( n N ) , k = 0 , 1 , ⋯ , r r = min n , M \begin{pmatrix} M \\ k \end{pmatrix}\begin{pmatrix} n-k \\ N-M \end{pmatrix}/\begin{pmatrix} n \\ N \end{pmatrix},k=0,1,\cdots,r \,\,r=\min{n,M} ( M k ) ( n − k N − M ) / ( n N ) , k = 0 , 1 , ⋯ , r r = min n , M n M N \textcolor{blue}{\frac{nM}{N}} N n M
G e ( p ) Ge(p) G e ( p ) ( 1 − p ) k − 1 p , k = 0 , 1 , ⋯ (1-p)^{k-1}p,k=0,1,\cdots ( 1 − p ) k − 1 p , k = 0 , 1 , ⋯ 1 p \textcolor{blue}{\frac{1}{p}} p 1
连续型随机变量:
分布
概率密度f ( x ) f(x) f ( x )
期望值
U ( a , b ) U(a,b) U ( a , b ) 1 / ( b − a ) , a < x < b 1/(b-a),a<x<b 1/ ( b − a ) , a < x < b ( b + a ) / 2 \textcolor{blue}{(b+a)/2} ( b + a ) /2
E x p ( λ ) Exp(\lambda) E x p ( λ ) λ e − λ x , x > 0 \lambda e^{-\lambda x},x>0 λ e − λ x , x > 0 1 / λ \textcolor{blue}{1/\lambda} 1/ λ
N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) 1 2 π σ e − ( x − μ ) 2 2 σ 2 , − ∞ < x < + ∞ \frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}},-\infty<x<+\infty 2 π σ 1 e − 2 σ 2 ( x − μ ) 2 , − ∞ < x < + ∞ μ \textcolor{blue}{\mu} μ
G a ( α , λ ) Ga(\alpha,\lambda) G a ( α , λ ) λ α Γ ( α ) x α − 1 e − λ x , x ≥ 0 \frac{\lambda^\alpha}{\Gamma(\alpha)}x^{\alpha-1}e^{-\lambda x},x\geq 0 Γ ( α ) λ α x α − 1 e − λ x , x ≥ 0 α / λ \textcolor{blue}{\alpha/\lambda} α / λ
χ 2 ( n ) \chi^2(n) χ 2 ( n ) x n / 2 − 1 2 n / 2 Γ ( n / 2 ) e − x / 2 , x > 0 \frac{x^{n/2-1}}{2^{n/2}\Gamma(n/2)}e^{-x/2},x>0 2 n /2 Γ ( n /2 ) x n /2 − 1 e − x /2 , x > 0 n \textcolor{blue}{n} n
B e ( a , b ) Be(a,b) B e ( a , b ) 1 B ( a , b ) x a − 1 ( 1 − x ) b − 1 , 0 < x < 1 \frac{1}{\Beta(a,b)}x^{a-1}(1-x)^{b-1},0<x<1 B ( a , b ) 1 x a − 1 ( 1 − x ) b − 1 , 0 < x < 1 a / ( a + b ) \textcolor{blue}{a/(a+b)} a / ( a + b )
C a u ( μ , λ ) Cau(\mu,\lambda) C a u ( μ , λ ) 1 π 1 1 + x 2 , − ∞ < x < + ∞ \frac{1}{\pi}\frac{1}{1+x^2},-\infty<x<+\infty π 1 1 + x 2 1 , − ∞ < x < + ∞ 不存在 \textcolor{blue}{不存在} 不存在
朗道分布 朗道分布 朗道分布 1 ξ ϕ ( λ ) \frac{1}{\xi}\phi(\lambda) ξ 1 ϕ ( λ ) 不存在 \textcolor{blue}{不存在} 不存在
9.2 随机函数的数学期望
对于n维随机变量函数g ( x ) g(\bm{x}) g ( x ) x \bm{x} x x x x g ( x ) g(\bm{x}) g ( x ) Z = g ( X , Y ) Z=g(X,Y) Z = g ( X , Y )
E ( Z ) = ∑ i , j g ( x i , y j ) p i j \mathrm{E}(Z)=\sum_{i,j}g(x_i,y_j)p_{ij}
E ( Z ) = i , j ∑ g ( x i , y j ) p ij
连续型期望为:
E ( Z ) = ∫ − ∞ + ∞ ∫ − ∞ + ∞ g ( x , y ) f ( x , y ) d x d y \mathrm{E}(Z)=\int_{-\infty}^{+\infty}\int_{-\infty}^{+\infty}g(x,y)f(x,y)dxdy
E ( Z ) = ∫ − ∞ + ∞ ∫ − ∞ + ∞ g ( x , y ) f ( x , y ) d x d y
接下来就可以引入一个比较重要也比较难的概念:
重期望公式:
设( X , Y ) (X,Y) ( X , Y ) E ( X ) \mathrm{E}(X) E ( X )
E ( X ) = E [ E ( X ∣ Y ) ] \mathrm{E}(X)=\textcolor{red}{\mathrm{E}}[\textcolor{blue}{\mathrm{E}}(\textcolor{blue}{X}|\textcolor{red}{Y})] E ( X ) = E [ E ( X ∣ Y )]
证明:
仅对连续型变量证明.设( X , Y ) (X,Y) ( X , Y ) f ( x , y ) f(x,y) f ( x , y ) g ( y ) = E ( X ∣ Y = y ) g(y)=\mathrm{E}(X|Y=y) g ( y ) = E ( X ∣ Y = y ) g ( Y ) = E ( X ∣ Y ) g(Y)=\mathrm{E}(X|Y) g ( Y ) = E ( X ∣ Y ) f ( x , y ) = f ( x ∣ y ) f Y ( y ) f(x,y)=f(x|y)f_Y(y) f ( x , y ) = f ( x ∣ y ) f Y ( y )
E ( X ) = ∫ − ∞ + ∞ ∫ − ∞ + ∞ x f ( x , y ) d x d y = ∫ − ∞ + ∞ ∫ − ∞ + ∞ x f ( x ∣ y ) f Y ( y ) d x d y = ∫ − ∞ + ∞ ( ∫ − ∞ + ∞ x f ( x ∣ y ) d x ) f Y ( y ) d y = ∫ − ∞ + ∞ E ( X ∣ Y = y ) f Y ( y ) d y = E [ E ( X ∣ Y ) ] \begin{aligned} \mathrm{E}(X)&=\int_{-\infty}^{+\infty}\int_{-\infty}^{+\infty}xf(x,y)dxdy=\int_{-\infty}^{+\infty}\int_{-\infty}^{+\infty}xf(x|y)f_Y(y)dxdy\\&=\int_{-\infty}^{+\infty}\left(\int_{-\infty}^{+\infty}xf(x|y)dx\right)f_Y(y)dy\\&=\int_{-\infty}^{+\infty}\mathrm{E}(X|Y=y)f_Y(y)dy\\&=\mathrm{E}[\mathrm{E}(X|Y)]\end{aligned} E ( X ) = ∫ − ∞ + ∞ ∫ − ∞ + ∞ x f ( x , y ) d x d y = ∫ − ∞ + ∞ ∫ − ∞ + ∞ x f ( x ∣ y ) f Y ( y ) d x d y = ∫ − ∞ + ∞ ( ∫ − ∞ + ∞ x f ( x ∣ y ) d x ) f Y ( y ) d y = ∫ − ∞ + ∞ E ( X ∣ Y = y ) f Y ( y ) d y = E [ E ( X ∣ Y )]
它表征了随机变量函数g ( Y ) = E ( X ∣ Y ) g(Y)=\mathrm{E}(X|Y) g ( Y ) = E ( X ∣ Y )
9.3 期望的性质
考虑a , C a,C a , C X , Y X,Y X , Y
期望的线性:
E ( C ) = C \mathrm{E}(C)=C E ( C ) = C E ( a X ) = a E ( X ) \mathrm{E}(aX)=a\mathrm{E}(X) E ( a X ) = a E ( X ) E ( X + Y ) = E ( X ) + E ( Y ) \mathrm{E}(X+Y)=\mathrm{E}(X)+\mathrm{E}(Y) E ( X + Y ) = E ( X ) + E ( Y ) 等效地有:
E ( ∑ i = 1 n a i X i + C ) = ∑ i = 1 n a i E ( X i ) + C \mathrm{E}\left(\sum_{i=1}^n a_iX_i+C\right)=\sum_{i=1}^n a_i\mathrm{E}(X_i)+C E ( i = 1 ∑ n a i X i + C ) = i = 1 ∑ n a i E ( X i ) + C
独立期望可乘:
当X , Y X,Y X , Y E ( X Y ) = E ( X ) E ( Y ) \mathrm{E}(XY)=\mathrm{E}(X)\mathrm{E}(Y) E ( X Y ) = E ( X ) E ( Y )
(注意:反过来不成立!)
9.4 例子
例9.3 (PMT接收总光子数)
光电倍增管(Photo-Multiplier Tube,PMT)是检测极微弱光的器件,在辐射测量、医学影像等领域应用广泛.N N N π ( λ ) \pi(\lambda) π ( λ ) Q Q Q G a ( α , λ 0 ) Ga(\alpha,\lambda_0) G a ( α , λ 0 ) E ( Y ) \mathrm{E}(Y) E ( Y )
解:
总电荷量Y = ∑ i = 1 N Q i = f ( N , Q i ) Y=\sum_{i=1}^N Q_i=f(N,Q_i) Y = ∑ i = 1 N Q i = f ( N , Q i ) Y Y Y N , Q N,Q N , Q
E ( Y ) = E [ E ( Y ∣ N ) ] \mathrm{E}(Y)=\mathrm{E}[\mathrm{E}(Y|N)] E ( Y ) = E [ E ( Y ∣ N )]
于是得到:
E ( Y ∣ N = n ) = ∑ i = 1 n E ( Q i ) = n E ( Q ) ⟹ E [ E ( Y ∣ N ) ] = E ( Q ) E ( N ) = α λ λ 0 \begin{aligned} \mathrm{E}(Y|N=n)&=\sum_{i=1}^{n}\mathrm{E}(Q_i)=n\mathrm{E}(Q)\\ \Longrightarrow \mathrm{E}[\mathrm{E}(Y|N)]&=\mathrm{E}(Q)\mathrm{E}(N)=\frac{\alpha\lambda}{\lambda_0}\end{aligned} E ( Y ∣ N = n ) ⟹ E [ E ( Y ∣ N )] = i = 1 ∑ n E ( Q i ) = n E ( Q ) = E ( Q ) E ( N ) = λ 0 α λ
L10 协方差
期望之后学方差,很合理~
10.1 方差
方差的定义
首先看方差的定义:
方差:
若E { ( X − E ( X ) 2 ) 2 } \mathrm{E}\{(X-\mathrm{E}(X)^2)^2\} E {( X − E ( X ) 2 ) 2 } X X X 方差 ,记作D ( X ) \mathrm{D}(X) D ( X ) V a r ( X ) \mathrm{Var}(X) Var ( X )
V a r ( X ) = E { ( X − E ( X ) 2 ) 2 } \mathrm{Var}(X)=\mathrm{E}\{(X-\mathrm{E}(X)^2)^2\} Var ( X ) = E {( X − E ( X ) 2 ) 2 }
V a r ( X ) \sqrt{\mathrm{Var}(X)} Var ( X ) X X X 标准差 或者均方差 ,它和X X X
方差的意义在于:描述随机变量X X X
一个常用的方差计算公式是:
方差计算公式:
V a r ( X ) = E ( X 2 ) − [ E ( X ) ] 2 \mathrm{Var}(X)=\mathrm{E}(X^2)-[\mathrm{E}(X)]^2 Var ( X ) = E ( X 2 ) − [ E ( X ) ] 2
从方差定义中看出它恒非负,因而获得一个边角料推论:
E ( X 2 ) ≥ [ E ( X ) ] 2 \mathrm{E}(X^2) \geq [\mathrm{E}(X)]^2
E ( X 2 ) ≥ [ E ( X ) ] 2
取等时当且仅当V a r ( X ) = 0 \mathrm{Var}(X)=0 Var ( X ) = 0
对随机变量X X X P ( X = x i ) = p i , i = 1 , 2 , . . . P(X=x_i)=p_i,i=1,2,... P ( X = x i ) = p i , i = 1 , 2 , ...
V a r ( X ) = ∑ i = 1 + ∞ [ x i − E ( X ) ] 2 p i \mathrm{Var}(X)=\sum_{i=1}^{+\infty}[x_i-\mathrm{E}(X)]^2p_i
Var ( X ) = i = 1 ∑ + ∞ [ x i − E ( X ) ] 2 p i
若是连续型的,概率密度为f ( x ) f(x) f ( x )
V a r ( X ) = ∫ − ∞ + ∞ [ x − E ( X ) ] 2 f ( x ) d x \mathrm{Var}(X)=\int_{-\infty}^{+\infty}[x-\mathrm{E}(X)]^2f(x)dx
Var ( X ) = ∫ − ∞ + ∞ [ x − E ( X ) ] 2 f ( x ) d x
方差的性质
方差的常用性质如下,其中a , b , C a,b,C a , b , C X , Y X,Y X , Y
方差的性质:
V a r ( C ) = 0 \mathrm{Var}(C)=0 Var ( C ) = 0
V a r ( a X + b ) = a 2 V a r ( X ) \mathrm{Var}(aX+b)=a^2\mathrm{Var}(X) Var ( a X + b ) = a 2 Var ( X )
V a r ( X ± Y ) = V a r ( X ) + V a r ( Y ) ± 2 E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] \mathrm{Var}(X \pm Y)=\mathrm{Var}(X)+ \mathrm{Var}(Y)\pm 2\mathrm{E}[(X-\mathrm{E}(X))(Y-\mathrm{E}(Y))] Var ( X ± Y ) = Var ( X ) + Var ( Y ) ± 2 E [( X − E ( X )) ( Y − E ( Y ))]
如果X , Y X,Y X , Y
V a r ( X ± Y ) = V a r ( X ) + V a r ( Y ) \mathrm{Var}(X \pm Y)=\mathrm{Var}(X)+ \mathrm{Var}(Y) Var ( X ± Y ) = Var ( X ) + Var ( Y )
V a r ( X ) = 0 ⟺ P [ X = E ( X ) ] = 1 \mathrm{Var}(X)=0 \Longleftrightarrow P[X=\mathrm{E}(X)]=1 Var ( X ) = 0 ⟺ P [ X = E ( X )] = 1
即X X X E ( X ) \mathrm{E}(X) E ( X )
∀ C , V a r ( X ) ≤ E [ ( X − C ) 2 ] \forall C,\mathrm{Var}(X)\leq \mathrm{E}[(X-C)^2] ∀ C , Var ( X ) ≤ E [( X − C ) 2 ]
即方差是E [ ( X − C ) 2 ] \mathrm{E}[(X-C)^2] E [( X − C ) 2 ] C = E ( X ) C=\mathrm{E}(X) C = E ( X )
值得一提的是,用性质四可见E ( X 2 ) ≥ [ E ( X ) ] 2 \mathrm{E}(X^2) \geq [\mathrm{E}(X)]^2 E ( X 2 ) ≥ [ E ( X ) ] 2
例10.1 (泊松分布)
X ∼ π ( λ ) X\sim \pi(\lambda) X ∼ π ( λ ) V a r ( X ) \mathrm{Var}(X) Var ( X )
解:
回忆:
E ( X ) = ∑ k = 0 + ∞ k ⋅ λ k k ! e − λ = λ e − λ ∑ k = 0 + ∞ k ⋅ λ k − 1 ( k − 1 ) ! = λ \mathrm{E}(X)=\sum_{k=0}^{+\infty}k\cdot\frac{\lambda^k}{k!}e^{-\lambda}=\lambda e^{-\lambda}\sum_{k=0}^{+\infty}k\cdot\frac{\lambda^{k-1}}{(k-1)!}=\lambda E ( X ) = k = 0 ∑ + ∞ k ⋅ k ! λ k e − λ = λ e − λ k = 0 ∑ + ∞ k ⋅ ( k − 1 )! λ k − 1 = λ
如法炮制得到
E ( X 2 ) = ∑ k = 0 + ∞ k 2 ⋅ λ k k ! e − λ = e − λ [ ∑ k = 0 + ∞ k ( k − 1 ) ⋅ λ k k ! + ∑ k = 0 + ∞ k ⋅ λ k k ! ] = λ ( λ + 1 ) \begin{aligned} \mathrm{E}(X^2) &=\sum_{k=0}^{+\infty}k^2\cdot\frac{\lambda^k}{k!}e^{-\lambda}\\ &=e^{-\lambda}\left[ \sum_{k=0}^{+\infty}k(k-1)\cdot\frac{\lambda^k}{k!}+\sum_{k=0}^{+\infty}k\cdot\frac{\lambda^k}{k!} \right]\\ &= \lambda(\lambda+1)\end{aligned} E ( X 2 ) = k = 0 ∑ + ∞ k 2 ⋅ k ! λ k e − λ = e − λ [ k = 0 ∑ + ∞ k ( k − 1 ) ⋅ k ! λ k + k = 0 ∑ + ∞ k ⋅ k ! λ k ] = λ ( λ + 1 )
于是V a r ( X ) = E ( X 2 ) − [ E ( X ) ] 2 = λ \mathrm{Var}(X)=\mathrm{E}(X^2)-[\mathrm{E}(X)]^2=\lambda Var ( X ) = E ( X 2 ) − [ E ( X ) ] 2 = λ
常见随机变量分布的方差
首先是离散型(超几何分布不作要求):
分布
概率分布P ( X = k ) P(X=k) P ( X = k )
方差
01分布
p k ( 1 − p ) k , k = 0 , 1 p^k(1-p)^k,k=0,1 p k ( 1 − p ) k , k = 0 , 1 p ( 1 − p ) \textcolor{blue}{p(1-p)} p ( 1 − p )
b ( n , p ) b(n,p) b ( n , p ) ( n k ) p k ( 1 − p ) n − k , k = 0 , 1 , ⋯ , n \begin{pmatrix} n \\ k \end{pmatrix}p^k(1-p)^{n-k},k=0,1,\cdots,n ( n k ) p k ( 1 − p ) n − k , k = 0 , 1 , ⋯ , n n p ( 1 − p ) \textcolor{blue}{np(1-p)} n p ( 1 − p )
π ( λ ) \pi(\lambda) π ( λ ) ( λ k / k ! ) e − λ , k = 0 , 1 , 2 , ⋯ (\lambda^k/k!)e^{-\lambda},k=0,1,2,\cdots ( λ k / k !) e − λ , k = 0 , 1 , 2 , ⋯ λ \textcolor{blue}{\lambda} λ
h ( n , M ) h(n,M) h ( n , M ) ( M k ) ( n − k N − M ) / ( n N ) , k = 0 , 1 , ⋯ , r r = min n , M \begin{pmatrix} M \\ k \end{pmatrix}\begin{pmatrix} n-k \\ N-M \end{pmatrix}/\begin{pmatrix} n \\ N \end{pmatrix},k=0,1,\cdots,r \,\,r=\min{n,M} ( M k ) ( n − k N − M ) / ( n N ) , k = 0 , 1 , ⋯ , r r = min n , M n M ( N − M ) ( N − n ) N 2 ( N − 1 ) \textcolor{blue}{\frac{nM(N-M)(N-n)}{N^2(N-1)}} N 2 ( N − 1 ) n M ( N − M ) ( N − n )
G e ( p ) Ge(p) G e ( p ) ( 1 − p ) k − 1 p , k = 0 , 1 , ⋯ (1-p)^{k-1}p,k=0,1,\cdots ( 1 − p ) k − 1 p , k = 0 , 1 , ⋯ 1 − p p 2 \textcolor{blue}{\frac{1-p}{p^2}} p 2 1 − p
连续型随机变量:
分布
概率密度f ( x ) f(x) f ( x )
方差
U ( a , b ) U(a,b) U ( a , b ) 1 / ( b − a ) , a < x < b 1/(b-a),a<x<b 1/ ( b − a ) , a < x < b ( b − a 2 ) / 12 \textcolor{blue}{(b-a^2)/12} ( b − a 2 ) /12
E x p ( λ ) Exp(\lambda) E x p ( λ ) λ e − λ x , x > 0 \lambda e^{-\lambda x},x>0 λ e − λ x , x > 0 1 / λ 2 \textcolor{blue}{1/\lambda^2} 1/ λ 2
N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) 1 2 π σ e − ( x − μ ) 2 2 σ 2 , − ∞ < x < + ∞ \frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}},-\infty<x<+\infty 2 π σ 1 e − 2 σ 2 ( x − μ ) 2 , − ∞ < x < + ∞ σ 2 \textcolor{blue}{\sigma^2} σ 2
G a ( α , λ ) Ga(\alpha,\lambda) G a ( α , λ ) λ α Γ ( α ) x α − 1 e − λ x , x ≥ 0 \frac{\lambda^\alpha}{\Gamma(\alpha)}x^{\alpha-1}e^{-\lambda x},x\geq 0 Γ ( α ) λ α x α − 1 e − λ x , x ≥ 0 α / λ 2 \textcolor{blue}{\alpha/\lambda^2} α / λ 2
χ 2 ( n ) \chi^2(n) χ 2 ( n ) x n / 2 − 1 2 n / 2 Γ ( n / 2 ) e − x / 2 , x > 0 \frac{x^{n/2-1}}{2^{n/2}\Gamma(n/2)}e^{-x/2},x>0 2 n /2 Γ ( n /2 ) x n /2 − 1 e − x /2 , x > 0 2 π \textcolor{blue}{2\pi} 2 π
B e ( a , b ) Be(a,b) B e ( a , b ) 1 B ( a , b ) x a − 1 ( 1 − x ) b − 1 , 0 < x < 1 \frac{1}{\Beta(a,b)}x^{a-1}(1-x)^{b-1},0<x<1 B ( a , b ) 1 x a − 1 ( 1 − x ) b − 1 , 0 < x < 1 a b ( a + b ) 2 ( a + b + 1 ) \textcolor{blue}{\frac{ab}{(a+b)^2(a+b+1)}} ( a + b ) 2 ( a + b + 1 ) ab
C a u ( μ , λ ) Cau(\mu,\lambda) C a u ( μ , λ ) 1 π 1 1 + x 2 , − ∞ < x < + ∞ \frac{1}{\pi}\frac{1}{1+x^2},-\infty<x<+\infty π 1 1 + x 2 1 , − ∞ < x < + ∞ 不存在 \textcolor{blue}{不存在} 不存在
朗道分布 朗道分布 朗道分布 1 ξ ϕ ( λ ) \frac{1}{\xi}\phi(\lambda) ξ 1 ϕ ( λ ) 不存在 \textcolor{blue}{不存在} 不存在
一个例子
例10.2 (提枪作战)
一个n n n X X X V a r ( X ) \mathrm{Var}(X) Var ( X )
解:
考虑分解问题:第i i i X i X_i X i i = 1 , 2 , 3 , . . . , n i=1,2,3,...,n i = 1 , 2 , 3 , ... , n
X i = { 0 没拿到自己枪 1 拿到自己枪 X_i=\begin{cases} 0 \,\,\,\, 没拿到自己枪\\ 1 \,\,\,\, 拿到自己枪\end{cases} X i = { 0 没拿到自己枪 1 拿到自己枪
容易看出X = ∑ i = 1 n X i X=\sum_{i=1}^n X_i X = ∑ i = 1 n X i X i X_i X i
V a r ( X ) = V a r ( ∑ i = 1 n X i ) = E [ ( ∑ i = 1 n X i ) 2 ] − [ E ( ∑ i = 1 n X i ) ] 2 = E ( ∑ i = 1 n X i 2 + 2 ∑ 1 ≤ i < j ≤ n X i X j ) − [ ∑ i = 1 n E ( X i ) ] 2 = n E ( X i 2 ) + n ( n − 1 ) E ( X i X j ) − n 2 E 2 ( X i ) \begin{aligned} \mathrm{Var}(X)=\mathrm{Var}\left(\sum_{i=1}^n X_i\right) &= \mathrm{E}\left[ \left( \sum_{i=1}^n X_i \right)^2 \right] - \left[\mathrm{E} \left( \sum_{i=1}^n X_i \right)\right]^2 \\ &= \mathrm{E}\left( \sum_{i=1}^n X_i^2 + 2\sum_{1\leq i<j\leq n} X_iX_j \right)-\left[\sum_{i=1}^n \mathrm{E}(X_i)\right]^2\\ &= n\mathrm{E}(X_i^2)+n(n-1)\mathrm{E}(X_iX_j)-n^2\mathrm{E}^2(X_i)\end{aligned} Var ( X ) = Var ( i = 1 ∑ n X i ) = E ( i = 1 ∑ n X i ) 2 − [ E ( i = 1 ∑ n X i ) ] 2 = E ( i = 1 ∑ n X i 2 + 2 1 ≤ i < j ≤ n ∑ X i X j ) − [ i = 1 ∑ n E ( X i ) ] 2 = n E ( X i 2 ) + n ( n − 1 ) E ( X i X j ) − n 2 E 2 ( X i )
最后一步式中i ≠ j i\neq j i = j E ( X i ) = E ( X i 2 ) = 1 n \mathrm{E}(X_i)=\mathrm{E}(X_i^2)=\frac{1}{n} E ( X i ) = E ( X i 2 ) = n 1 X i X j X_iX_j X i X j
若i , j i,j i , j X i X j = 1 X_iX_j=1 X i X j = 1 P ( X i X j = 1 ) = n ( n − 1 ) P(X_iX_j=1)=\frac{n}{(n-1)} P ( X i X j = 1 ) = ( n − 1 ) n E ( X i X j ) = n ( n − 1 ) \mathrm{E}(X_iX_j)=\frac{n}{(n-1)} E ( X i X j ) = ( n − 1 ) n
带入原式,我们得到:
V a r ( X ) = 1 \mathrm{Var}(X)=1 Var ( X ) = 1
拓展一下,恰有k ( k < n ) k(k<n) k ( k < n )
求解全错排问题: n n n A n A_n A n p n = A n n ! p_n=\frac{A_n}{n!} p n = n ! A n 将我们的问题转化为全错排问题:先选k k k ( n k ) \begin{pmatrix}n\\k\end{pmatrix} ( n k ) ( n − k ) (n-k) ( n − k ) ( n − k ) (n-k) ( n − k ) P n = ( n k ) p n − k P_n=\begin{pmatrix}n\\k\end{pmatrix}p_{n-k} P n = ( n k ) p n − k 具体形式略.
10.2 全方差公式
我们知道全期望公式:用条件概率计算期望,从而让大随机变量被分解到小随机变量.对方差能不能也这么干?
考虑北京某月的总降雨量S S S N N N R R R V a r ( S ) = V a r V a r ( S ∣ N ) \mathrm{Var}(S)=\mathrm{Var}\mathrm{Var}(S|N) Var ( S ) = Var Var ( S ∣ N ) 量纲都不匹配 ,肯定是错的!
那要怎么让量纲匹配呢?或许把期望E \mathrm{E} E S ∣ N S|N S ∣ N 对称性 .
或者说,是两者的线性组合?
别误会,我们当然可以严格地理论证明出这个关系,但是在证明之前,我们可以先和这个概念培养一下感情,让我们对这个概念有一个初步的感觉.(这亦是一种"Fly By Night Probability".)
全方差公式:
V a r ( S ) = E [ V a r ( S ∣ N ) ] ⏞ N 固定时 S 的方差 + V a r [ E ( S ∣ N ) ] ⏞ 由 N 诱导出的 S 方差 \mathrm{Var}(S)=\overbrace{\mathrm{E}[\mathrm{Var}(S|N)]}^{N固定时S的方差}+\overbrace{\mathrm{Var}[\mathrm{E}(S|N)]}^{由N诱导出的S方差} Var ( S ) = E [ Var ( S ∣ N )] N 固定时 S 的方差 + Var [ E ( S ∣ N )] 由 N 诱导出的 S 方差
证明:
方差的期望:
E [ V a r ( S ∣ N ) ] = E N [ E S ( S 2 ∣ N ) − E S ( S ∣ N ) 2 ] = E ( S 2 ) − E N [ E S ( S ∣ N ) 2 ] \begin{aligned} \mathrm{E}[\mathrm{Var}(S|N)]&=\mathrm{E}_N[\mathrm{E}_S(S^2|N)-\mathrm{E}_S(S|N)^2]\\ &=\mathrm{E}(S^2)-\mathrm{E}_N[\mathrm{E}_S(S|N)^2]\end{aligned} E [ Var ( S ∣ N )] = E N [ E S ( S 2 ∣ N ) − E S ( S ∣ N ) 2 ] = E ( S 2 ) − E N [ E S ( S ∣ N ) 2 ]
期望的方差:
V a r [ E ( S ∣ N ) ] = E N [ E S ( S ∣ N ) 2 ] − { E N [ E S ( S ∣ N ) ] } 2 = E N [ E S ( S ∣ N ) 2 ] − [ E ( S ) ] 2 \begin{aligned} \mathrm{Var}[\mathrm{E}(S|N)]&=\mathrm{E}_N[\mathrm{E}_S(S|N)^2]-\{\mathrm{E}_N[\mathrm{E}_S(S|N)]\}^2\\ &=\mathrm{E}_N[\mathrm{E}_S(S|N)^2]-[\mathrm{E}(S)]^2\end{aligned} Var [ E ( S ∣ N )] = E N [ E S ( S ∣ N ) 2 ] − { E N [ E S ( S ∣ N )] } 2 = E N [ E S ( S ∣ N ) 2 ] − [ E ( S ) ] 2
一眼盯真,我们发现:
V a r ( S ) = E [ V a r ( S ∣ N ) ] + V a r [ E ( S ∣ N ) ] \mathrm{Var}(S)=\mathrm{E}[\mathrm{Var}(S|N)]+\mathrm{Var}[\mathrm{E}(S|N)] Var ( S ) = E [ Var ( S ∣ N )] + Var [ E ( S ∣ N )]
这就是全方差公式.
这个定理在高斯的书中(Theoria Combinationis 1821,1823)被证明.高斯在1801年用"最小二乘法"预测了谷神星的存在,但其理论基础遭到质疑.于是,在书中,高斯在不对N , S N,S N , S
这个公式很有用,我们仍然回到光电倍增管总电荷的问题:
例10.3 (光电倍增管再看)
Y = ∑ i = 1 N Q i Y=\sum_{i=1}^{N}Q_i Y = ∑ i = 1 N Q i V a r ( Y ) \mathrm{Var}(Y) Var ( Y )
解:
总电荷量Y Y Y
V a r ( Y ) = E [ V a r ( Y ∣ N ) ] + V a r [ E ( Y ∣ N ) ] = E [ N V a r ( Q ) ] + V a r [ N E ( Q ) ] = E ( N ) V a r ( Q ) + V a r ( N ) [ E ( Q ) 2 ] \begin{aligned} \mathrm{Var}(Y)&=\mathrm{E}[\mathrm{Var}(Y|N)]+\mathrm{Var}[\mathrm{E}(Y|N)]\\ &=\mathrm{E}[N\mathrm{Var}(Q)]+\mathrm{Var}[N\mathrm{E}(Q)]\\ &=\mathrm{E}(N)\mathrm{Var}(Q)+\mathrm{Var}(N)[\mathrm{E}(Q)^2]\end{aligned} Var ( Y ) = E [ Var ( Y ∣ N )] + Var [ E ( Y ∣ N )] = E [ N Var ( Q )] + Var [ N E ( Q )] = E ( N ) Var ( Q ) + Var ( N ) [ E ( Q ) 2 ]
10.3 协方差
回忆:
二维随机变量( X , Y ) (X,Y) ( X , Y )
二维随机变量,除了每个随机变量各自的边缘分布外,相互之间还有联系.
考虑两个随机变量X , Y X,Y X , Y
V a r ( X ± Y ) = V a r ( X ) + V a r ( Y ) ± 2 E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] \mathrm{Var}(X \pm Y)=\mathrm{Var}(X)+ \mathrm{Var}(Y)\pm 2\mathrm{E}[(X-\mathrm{E}(X))(Y-\mathrm{E}(Y))]
Var ( X ± Y ) = Var ( X ) + Var ( Y ) ± 2 E [( X − E ( X )) ( Y − E ( Y ))]
其中E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] \mathrm{E}[(X-\mathrm{E}(X))(Y-\mathrm{E}(Y))] E [( X − E ( X )) ( Y − E ( Y ))]
协方差的定义
我们定义:
协方差与相关系数:
随机变量X , Y X,Y X , Y 协方差 记作C o v ( X , Y ) \mathrm{Cov}(X,Y) Cov ( X , Y )
C o v ( X , Y ) : = E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] = E ( X Y ) − E ( X ) E ( Y ) \mathrm{Cov}(X,Y):=\mathrm{E}[(X-\mathrm{E}(X))(Y-\mathrm{E}(Y))]=\mathrm{E}(XY)-\mathrm{E}(X)\mathrm{E}(Y) Cov ( X , Y ) := E [( X − E ( X )) ( Y − E ( Y ))] = E ( X Y ) − E ( X ) E ( Y )
我们还可以把协方差标准化为无量纲的数:由于V a r ( X ) , V a r ( Y ) > 0 \mathrm{Var}(X),\mathrm{Var}(Y)>0 Var ( X ) , Var ( Y ) > 0 X , Y X,Y X , Y 相关系数 ρ X , Y \rho_{X,Y} ρ X , Y
ρ X , Y = E ( [ X − E ( X ) ] [ Y − E ( Y ) ] V a r ( X ) V a r ( Y ) ) = C o v ( X , Y ) V a r ( X ) V a r ( Y ) \rho_{X,Y}=\mathrm{E}\left(\frac{[X-\mathrm{E}(X)][Y-\mathrm{E}(Y)]}{\sqrt{\mathrm{Var}(X)\mathrm{Var}(Y)}}\right)=\frac{\mathrm{Cov}(X,Y)}{\sqrt{\mathrm{Var}(X)\mathrm{Var}(Y)}} ρ X , Y = E ( Var ( X ) Var ( Y ) [ X − E ( X )] [ Y − E ( Y )] ) = Var ( X ) Var ( Y ) Cov ( X , Y )
若ρ X Y = 0 \rho_{XY}=0 ρ X Y = 0 C o v ( X , Y ) = 0 \mathrm{Cov}(X,Y)=0 Cov ( X , Y ) = 0 X , Y X,Y X , Y 不相关 .
两随机变量不相关,与两随机变量独立有什么关系?回到定义:
不相关:ρ X Y = 0 \rho_{XY}=0 ρ X Y = 0
独立:F ( X , Y ) = F X ( x ) F Y ( y ) F(X,Y)=F_X(x)F_Y(y) F ( X , Y ) = F X ( x ) F Y ( y ) 两随机变量独立能推出不相关,但反之不行 .
一个直观的想法是,不相关等价于E ( X Y ) = E ( X ) E ( Y ) \mathrm{E}(XY)=\mathrm{E}(X)\mathrm{E}(Y) E ( X Y ) = E ( X ) E ( Y )
协方差的性质
协方差的性质:
计算:
C o v ( X , Y ) = E ( X Y ) − E ( X ) E ( Y ) = ± 1 2 [ V a r ( X ± Y ) − V a r ( X ) − V a r ( Y ) ] \mathrm{Cov}(X,Y)=\mathrm{E}(XY)-\mathrm{E}(X)\mathrm{E}(Y)=\pm\frac{1}{2}[\mathrm{Var}(X\pm Y)-\mathrm{Var}(X)-\mathrm{Var}(Y)] Cov ( X , Y ) = E ( X Y ) − E ( X ) E ( Y ) = ± 2 1 [ Var ( X ± Y ) − Var ( X ) − Var ( Y )]
对称性: C o v ( X , Y ) = C o v ( Y , X ) \mathrm{Cov}(X,Y)=\mathrm{Cov}(Y,X) Cov ( X , Y ) = Cov ( Y , X )
双线性: C o v ( a X + b , Y ) = a C o v ( X , Y ) + b \mathrm{Cov}(aX+b,Y)=a\mathrm{Cov}(X,Y)+b Cov ( a X + b , Y ) = a Cov ( X , Y ) + b
C o v ( X , X ) = V a r ( X ) \mathrm{Cov}(X,X)=\mathrm{Var}(X) Cov ( X , X ) = Var ( X )
即,方差是协方差的特例 .
利用这些性质,我们可以解释一下何为相关系数:
标准化随机变量:
随机变量X X X 标准化随机变量 记作:
X ∗ : = X − E ( X ) V a r ( X ) X^*:=\frac{X-\mathrm{E}(X)}{\sqrt{\mathrm{Var}(X)}} X ∗ := Var ( X ) X − E ( X )
对标准化随机变量,E ( X ∗ ) = 0 , V a r ( X ∗ ) = 1 \mathrm{E}(X^*)=0,\mathrm{Var}(X^*)=1 E ( X ∗ ) = 0 , Var ( X ∗ ) = 1
C o v ( X ∗ , Y ∗ ) = ρ X Y \mathrm{Cov}(X^*,Y^*)=\rho_{XY} Cov ( X ∗ , Y ∗ ) = ρ X Y
顺便讨论一下相关系数的性质:
相关系数的性质:
∣ ρ X Y ∣ ≤ 1 |\rho_{XY}|\leq 1 ∣ ρ X Y ∣ ≤ 1
∣ ρ X Y ∣ = 1 ⟺ |\rho_{XY}|=1\Longleftrightarrow ∣ ρ X Y ∣ = 1 ⟺ a , b a,b a , b P ( Y = a X + b ) = 1 P(Y=aX+b)=1 P ( Y = a X + b ) = 1
即,X , Y X,Y X , Y
若X , Y X,Y X , Y ρ X Y = 0 \rho_{XY}=0 ρ X Y = 0 X , Y X,Y X , Y
需要指出的是,前两条性质我们在中学中线性回归一节已经了解过,但它没那么显然,需要进一步证明:
证明:
首先证明期望的Cauchy-Schwartz不等式:[ E ( X Y ) ] 2 ≤ E ( X 2 ) E ( Y 2 ) [\mathrm{E}(XY)]^2\leq\mathrm{E}(X^2)\mathrm{E}(Y^2) [ E ( X Y ) ] 2 ≤ E ( X 2 ) E ( Y 2 )
天下实内积C-S不等式的证法都是统一的:考虑实变量t t t
g ( t ) = E [ ( X + t Y ) 2 ] = E ( X 2 ) + 2 t E ( X Y ) + t 2 E ( Y 2 ) ≥ 0 g(t)=\mathrm{E}[(X+tY)^2]=\mathrm{E}(X^2)+2t\mathrm{E}(XY)+t^2\mathrm{E}(Y^2)\geq 0 g ( t ) = E [( X + t Y ) 2 ] = E ( X 2 ) + 2 t E ( X Y ) + t 2 E ( Y 2 ) ≥ 0
用二次方程g ( t ) = 0 g(t)=0 g ( t ) = 0
将标准化的X ∗ , Y ∗ X^*,Y^* X ∗ , Y ∗
∣ ρ X Y ∣ = ∣ E ( X ∗ Y ∗ ) ∣ ≤ E ( X ∗ ) E ( Y ∗ ) = 1 |\rho_{XY}|=|\mathrm{E}(X^*Y^*)|\leq\sqrt{\mathrm{E}(X^*)\mathrm{E}(Y^*)}=1 ∣ ρ X Y ∣ = ∣ E ( X ∗ Y ∗ ) ∣ ≤ E ( X ∗ ) E ( Y ∗ ) = 1
协方差矩阵
我们把协方差扩展到n n n
协方差矩阵、相关系数矩阵:
设n n n X = ( X 1 , X 2 , . . . , X n ) \bm{X}=(X_1,X_2,...,X_n) X = ( X 1 , X 2 , ... , X n )
[ V a r ( X 1 ) C o v ( X 1 , X 2 ) ⋯ C o v ( X 1 , X n ) C o v ( X 2 , X 1 ) V a r ( X 2 ) ⋯ C o v ( X 2 , X n ) ⋮ ⋮ ⋱ ⋮ C o v ( X n , X 1 ) C o v ( X n , X 2 ) ⋯ V a r ( X n ) ] \begin{bmatrix} \mathrm{Var}(X_1) & \mathrm{Cov}(X_1,X_2)&\cdots &\mathrm{Cov}(X_1,X_n)\\ \mathrm{Cov}(X_2,X_1) & \mathrm{Var}(X_2)&\cdots &\mathrm{Cov}(X_2,X_n)\\ \vdots&\vdots&\ddots&\vdots\\ \mathrm{Cov}(X_n,X_1) & \mathrm{Cov}(X_n,X_2)&\cdots &\mathrm{Var}(X_n)\\\end{bmatrix} Var ( X 1 ) Cov ( X 2 , X 1 ) ⋮ Cov ( X n , X 1 ) Cov ( X 1 , X 2 ) Var ( X 2 ) ⋮ Cov ( X n , X 2 ) ⋯ ⋯ ⋱ ⋯ Cov ( X 1 , X n ) Cov ( X 2 , X n ) ⋮ Var ( X n )
为这组随机变量的协方差矩阵 ,也称为方差-协方差矩阵 ,记为V a r ( X ) \mathrm{Var}(\bm{X}) Var ( X ) X − E ( X ) \bm{X}-\mathrm{E}(\bm{X}) X − E ( X ) n n n
V a r ( X ) = E { [ X − E ( X ) ] [ X − E ( X ) ] ⊤ } \mathrm{Var}(\bm{X})=\mathrm{E}\{[\bm{X}-\mathrm{E}(\bm{X})][\bm{X}-\mathrm{E}(\bm{X})]^\top\} Var ( X ) = E {[ X − E ( X )] [ X − E ( X ) ] ⊤ }
这是一个对称、非负定的矩阵.(如果你对这句话有疑问,说明你该小复习一下线代了)
对应地,记ρ i , j = C o v ( X i , X j ) V a r ( X i ) V a r ( X j ) , i , j = 1 , 2 , . . . , n \rho_{i,j}=\frac{\mathrm{Cov}(X_i,X_j)}{\sqrt{\mathrm{Var}(X_i)\mathrm{Var}(X_j)}},i,j=1,2,...,n ρ i , j = Var ( X i ) Var ( X j ) Cov ( X i , X j ) , i , j = 1 , 2 , ... , n
[ ρ 11 ρ 12 ⋯ ρ 1 n ρ 21 ρ 22 ⋯ ρ 2 n ⋮ ⋮ ⋱ ⋮ ρ n 1 ρ n 2 ⋯ ρ n n ] \begin{bmatrix} \rho_{11} & \rho_{12}&\cdots &\rho_{1n}\\ \rho_{21} & \rho_{22}&\cdots &\rho_{2n}\\ \vdots&\vdots&\ddots&\vdots\\ \rho_{n1} & \rho_{n2}&\cdots &\rho_{nn}\\\end{bmatrix} ρ 11 ρ 21 ⋮ ρ n 1 ρ 12 ρ 22 ⋮ ρ n 2 ⋯ ⋯ ⋱ ⋯ ρ 1 n ρ 2 n ⋮ ρ nn
为相关系数矩阵 ,简称相关矩阵 ,它同样是对称、非负定的
利用协方差矩阵,我们可以重新审视一下我们之前处理过的二维正态分布:考虑X ∼ N ( μ 1 , σ 1 2 ; μ 2 , σ 2 2 ; ρ ) \bm{X}\sim N(\mu_1,\sigma_1^2;\mu_2,\sigma_2^2;\rho) X ∼ N ( μ 1 , σ 1 2 ; μ 2 , σ 2 2 ; ρ ) Σ 2 = V a r ( X ) , μ = E ( X ) , x = ( x 1 , x 2 ) ⊤ \Sigma^2=\mathrm{Var}(\bm{X}),\bm{\mu}=\mathrm{E}(\bm{X}),\bm{x}=(x_1,x_2)^\top Σ 2 = Var ( X ) , μ = E ( X ) , x = ( x 1 , x 2 ) ⊤
Σ 2 = V a r ( X ) = [ σ 1 2 ρ σ 1 σ 2 ρ σ 1 σ 2 σ 2 2 ] \Sigma^2=\mathrm{Var}(\bm{X})=\begin{bmatrix}
\sigma_1^2&\rho\sigma_1\sigma_2\\
\rho\sigma_1\sigma_2&\sigma_2^2\\
\end{bmatrix}
Σ 2 = Var ( X ) = [ σ 1 2 ρ σ 1 σ 2 ρ σ 1 σ 2 σ 2 2 ]
我们有:
f ( x , y ) = 1 2 π σ 1 σ 2 1 − ρ 2 e − 1 2 ( 1 − ρ 2 ) [ ( x 1 − μ 1 ) 2 σ 1 2 − 2 ρ ( x 1 − μ 1 ) ( x 2 − μ 2 ) σ 1 σ 2 + ( x 2 − μ 2 ) 2 σ 2 2 ] = 1 2 π ∣ Σ 2 ∣ e − 1 2 ( x − μ ) ⊤ Σ − 2 ( x − μ ) \begin{aligned}
f(x,y)&=\frac{1}{2\pi\sigma_1\sigma_2\sqrt{1-\rho^2}}e^{-\frac{1}{2(1-\rho^2)}\left[\frac{(x_1-\mu_1)^2}{\sigma_1^2}-2\rho\frac{(x_1-\mu_1)(x_2-\mu_2)}{\sigma_1\sigma_2}+\frac{(x_2-\mu_2)^2}{\sigma_2^2}\right]}\\
&=\frac{1}{2\pi\sqrt{|\Sigma^2|}}e^{-\frac{1}{2}(\bm{x}-\bm{\mu})^\top\Sigma^{-2}(\bm{x}-\bm{\mu})}
\end{aligned}
f ( x , y ) = 2 π σ 1 σ 2 1 − ρ 2 1 e − 2 ( 1 − ρ 2 ) 1 [ σ 1 2 ( x 1 − μ 1 ) 2 − 2 ρ σ 1 σ 2 ( x 1 − μ 1 ) ( x 2 − μ 2 ) + σ 2 2 ( x 2 − μ 2 ) 2 ] = 2 π ∣ Σ 2 ∣ 1 e − 2 1 ( x − μ ) ⊤ Σ − 2 ( x − μ )
当正态分布中x \bm{x} x 高斯过程 (随机过程 的一种,可以看做随机的函数:R → ( S → R ) \mathbb{R}\rightarrow(S\rightarrow\mathbb{R}) R → ( S → R ) ( S → R ) (S\rightarrow\mathbb{R}) ( S → R )
10.4 其他数字特征
原点矩、中心矩
原点矩和中心矩:
设X X X k k k
μ k : = E ( X k ) \mu_k:=\mathrm{E}(X^k) μ k := E ( X k )
为X X X k k k 原点矩 .称:
ν k : = E { [ X − E ( X ) ] k } \nu_k:=\mathrm{E}\{[X-\mathrm{E}(X)]^k\} ν k := E {[ X − E ( X ) ] k }
为X X X k k k 中心矩 .1阶原点矩为数学期望,2阶中心矩为方差.
中心矩与原点矩的关系可以用二项式定理得到:
ν k = E { [ X − E ( X ) ] k } = E [ ( X − μ 1 ) k ] = ∑ i = 0 k ( k i ) μ i ( − μ 1 ) k − i \nu_k=\mathrm{E}\{[X-\mathrm{E}(X)]^k\}=\mathrm{E}[(X-\mu_1)^k]=\sum_{i=0}^k \begin{pmatrix} k \\ i\end{pmatrix}\mu_i(-\mu_1)^{k-i} ν k = E {[ X − E ( X ) ] k } = E [( X − μ 1 ) k ] = i = 0 ∑ k ( k i ) μ i ( − μ 1 ) k − i
混合矩
混合矩即将原点矩、中心矩推广到多维随机变量的情形,下面以2维为例.
混合矩:
设X , Y X,Y X , Y k , l k,l k , l
μ k l : = E ( X k Y l ) \mu_{kl}:=\mathrm{E}(X^kY^l) μ k l := E ( X k Y l )
为( X , Y ) (X,Y) ( X , Y ) k + l k+l k + l 混合原点矩 ,简称混合矩 .称:
ν k l : = E { [ X − E ( X ) ] k [ Y − E ( Y ) ] l } \nu_{kl}:=\mathrm{E}\{[X-\mathrm{E}(X)]^k[Y-\mathrm{E}(Y)]^l\} ν k l := E {[ X − E ( X ) ] k [ Y − E ( Y ) ] l }
为( X , Y ) (X,Y) ( X , Y ) k + l k+l k + l 混合中心矩 .1+1阶混合中心矩为X , Y X,Y X , Y
基于矩的其他数字特征
3阶矩可以定义偏度系数(skew):
偏度系数:
设X X X
β s : = ν 3 ν 2 3 2 = E { [ X − E ( X ) ] 3 } [ V a r ( X ) ] 3 2 \beta_{s}:=\frac{\nu_3}{\nu_2^{\frac{3}{2}}}=\frac{\mathrm{E}\{[X-\mathrm{E}(X)]^3\}}{[\mathrm{Var}(X)]^{\frac{3}{2}}} β s := ν 2 2 3 ν 3 = [ Var ( X ) ] 2 3 E {[ X − E ( X ) ] 3 }
为( X , Y ) (X,Y) ( X , Y ) 偏度系数 ,简称偏度 .
β s \beta_s β s β s > 0 \beta_s>0 β s > 0 β s < 0 \beta_s<0 β s < 0
β s = 0 \beta_s=0 β s = 0 β s = 0 \beta_s=0 β s = 0
4阶矩可以定义峰度系数(kurtosis):
峰度系数:
设X X X
β k : = ν 4 ν 2 2 = E { [ X − E ( X ) ] 4 } [ V a r ( X ) ] 2 \beta_{k}:=\frac{\nu_4}{\nu_2^2}=\frac{\mathrm{E}\{[X-\mathrm{E}(X)]^4\}}{[\mathrm{Var}(X)]^2} β k := ν 2 2 ν 4 = [ Var ( X ) ] 2 E {[ X − E ( X ) ] 4 }
为( X , Y ) (X,Y) ( X , Y ) 峰度系数 ,简称峰度 .
β k \beta_k β k
正态分布的β k = 0 \beta_k=0 β k = 0
以上两个系数常常用于检测正态假设是否可接受.
L11 大数定律
考虑大数定律至少有两个动机:我们为什么能以某事件发生的频率作为该事件概率的估计?
柯氏概率公理中并不包含概率的解读,这个命题不是自证的.
11.1 大数定律
辛钦大数定律
首先复习一下极限lim n → ∞ X n = X \lim_{n\rightarrow\infty}X_n=X lim n → ∞ X n = X
∀ ϵ > 0 , ∃ N ( n > N → ∣ X n − X ∣ < ϵ ) \forall\epsilon>0,\exists N(n>N\rightarrow|X_n-X|<\epsilon)
∀ ϵ > 0 , ∃ N ( n > N → ∣ X n − X ∣ < ϵ )
依概率收敛:
设X n X_n X n X X X ϵ \epsilon ϵ
lim n → ∞ P ( ∣ X n − X ∣ < ϵ ) → 1 \lim_{n\rightarrow\infty}P(|X_n-X|<\epsilon)\rightarrow1 n → ∞ lim P ( ∣ X n − X ∣ < ϵ ) → 1
亦即
∀ ϵ > 0 , ϵ ′ > 0 , ∃ N ( n > N → 1 − P ( ∣ X n − X ∣ < ϵ ) < ϵ ′ ) \forall\epsilon>0,\epsilon'>0,\exists N(n>N\rightarrow1-P(|X_n-X|<\epsilon)<\epsilon') ∀ ϵ > 0 , ϵ ′ > 0 , ∃ N ( n > N → 1 − P ( ∣ X n − X ∣ < ϵ ) < ϵ ′ )
则称随机变量序列X n X_n X n 依概率收敛 于X X X
X n → P X X_n\stackrel{P}{\rightarrow}X X n → P X
依概率收敛定义了随机变量层面的极限操作.
于是我们可以给出辛钦(Khinchin)版本的大数定律:
辛钦大数定律:
设X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X 1 , X 2 , ... , X n E ( X k ) = μ , k = 1 , 2 , . . . , n \mathrm{E}(X_k)=\mu,k=1,2,...,n E ( X k ) = μ , k = 1 , 2 , ... , n ϵ \epsilon ϵ
lim n → ∞ P ( ∣ 1 n ∑ i = 1 n X i − μ ∣ < ϵ ) = 1 \lim_{n\rightarrow\infty}P\left( \left|\frac{1}{n}\sum_{i=1}^nX_i - \mu\right| <\epsilon\right) = 1 n → ∞ lim P ( n 1 i = 1 ∑ n X i − μ < ϵ ) = 1
如果记X n ˉ = 1 n ∑ i = 1 n X i \bar{X_n}=\frac{1}{n}\sum_{i=1}^nX_i X n ˉ = n 1 ∑ i = 1 n X i
X n ˉ → P μ \bar{X_n}\stackrel{P}{\rightarrow}\mu X n ˉ → P μ
辛钦大数定律表明:数学期望可以用n n n
这个定律的证明暂且按下不表,我们先看下一个大数定律:伯努利(Bernoulli)大数定律.
伯努利大数定律
伯努利大数定律:
设n A n_A n A n n n A A A p p p A A A
∀ ϵ > 0 , lim n → ∞ P ( ∣ n A n − p ∣ < ϵ ) = 1 \forall\epsilon>0,\lim_{n\rightarrow\infty}P\left(\left|\frac{n_A}{n}-p\right|<\epsilon\right)=1 ∀ ϵ > 0 , n → ∞ lim P ( n n A − p < ϵ ) = 1
证明:
利用辛钦大数定律可以给出证明.因为n = X 1 + X 2 + . . . + X n n=X_1+X_2+...+X_n n = X 1 + X 2 + ... + X n p p p E ( X k ) = p , k = 1 , 2 , . . . , n \mathrm{E}(X_k)=p,k=1,2,...,n E ( X k ) = p , k = 1 , 2 , ... , n
lim n → ∞ P ( ∣ n A n − p ∣ < ϵ ) = lim n → ∞ P ( ∣ 1 n ∑ i = 1 n X i − p ∣ < ϵ ) = 1 \lim_{n\rightarrow\infty}P\left(\left|\frac{n_A}{n}-p\right|<\epsilon\right) = \lim_{n\rightarrow\infty}P\left( \left|\frac{1}{n}\sum_{i=1}^nX_i - p\right| <\epsilon\right)= 1 n → ∞ lim P ( n n A − p < ϵ ) = n → ∞ lim P ( n 1 i = 1 ∑ n X i − p < ϵ ) = 1
我们的证法中,伯努利的大数定律好像只是辛钦大数定律的一个推论,然而事实上这件事意义重大:它告诉我们,在实验次数足够多后,频率与概率由较大偏差是小概率事件,因而可以用频率近似替代概率 .
概率公理 ⟶ 辛钦大数定律 平均趋于期望 ⟶ 伯努利大数定律 频率趋于概率 概率公理\stackrel{辛钦大数定律}{\longrightarrow}平均趋于期望\stackrel{伯努利大数定律}{\longrightarrow}频率趋于概率
概率公理 ⟶ 辛钦大数定律 平均趋于期望 ⟶ 伯努利大数定律 频率趋于概率
上图直观地展示了这两个定理的重要性:
概率公理构造的"概率"是满足我们对于概率的一般认识的(即"频率趋近概率"),而不会像频率定义概率那样陷入循环论证.
我们既可以从概率推出期望,也能用期望推出概率,这暗示着这两个概念是等价的 ,我们完全可以用"期望公理"推出概率.
大数定律让我们从随机 的现象(均值与频率)中找到了确定 的值(期望与概率).
因而,这两个定律堪称概率论的基石.
同时,上图也指出了我们接下来的方向:用概率公理推出辛钦大数定律.我们会介绍两种证明方法:切比雪夫不等式、特征函数.
11.2 切比雪夫不等式
切比雪夫不等式及证明
切比雪夫Chebyshev不等式:
设随机变量X X X E ( X ) = μ \mathrm{E}(X)=\mu E ( X ) = μ V a r ( X ) = σ 2 \mathrm{Var}(X)=\sigma^2 Var ( X ) = σ 2
∀ ϵ > 0 , P ( ∣ X − μ ∣ ≥ ϵ ) ≤ σ 2 ϵ 2 \forall\epsilon>0,P(|X-\mu|\geq\epsilon)\leq\frac{\sigma^2}{\epsilon^2} ∀ ϵ > 0 , P ( ∣ X − μ ∣ ≥ ϵ ) ≤ ϵ 2 σ 2
证明:
仅考虑连续变量情形.设X X X f ( x ) f(x) f ( x )
P ( ∣ X − μ ∣ ≥ ϵ ) = ∫ ∣ x − μ ∣ ≥ ϵ f ( x ) d x ≤ ∫ ∣ x − μ ∣ ≥ ϵ ∣ x − μ ∣ 2 ϵ 2 f ( x ) d x = σ 2 ϵ 2 \begin{aligned} P(|X-\mu|\geq\epsilon) &= \int_{|x-\mu|\geq\epsilon}f(x)dx \\ &\leq \int_{|x-\mu|\geq\epsilon}\frac{|x-\mu|^2}{\epsilon^2}f(x)dx \\ &= \frac{\sigma^2}{\epsilon^2}\end{aligned} P ( ∣ X − μ ∣ ≥ ϵ ) = ∫ ∣ x − μ ∣ ≥ ϵ f ( x ) d x ≤ ∫ ∣ x − μ ∣ ≥ ϵ ϵ 2 ∣ x − μ ∣ 2 f ( x ) d x = ϵ 2 σ 2
第二步不等式放缩是关键.证毕.
切比雪夫不等式可以让我们在未知随机变量X X X ∣ X − μ ∣ < ϵ |X-\mu|<\epsilon ∣ X − μ ∣ < ϵ X X X
但适用范围的广延让它在理论上意义非凡,它启示我们:一个随机变量的方差存在,就是一个很强的条件,足以让我们对某事件的概率有一个界的估计,即使它是一个比较任意的分布.
同样地,辛钦大数定律也可以用它证明:
切比雪夫不等式到大数定律
辛钦大数定律证明1:
往证:
X n ˉ = 1 n ∑ i = 1 n X i → P μ \bar{X_n}=\frac{1}{n}\sum_{i=1}^nX_i\stackrel{P}{\rightarrow}\mu X n ˉ = n 1 i = 1 ∑ n X i → P μ
我们还要加强原有假设 :V a r ( X k ) = σ 2 \mathrm{Var}(X_k)=\sigma^2 Var ( X k ) = σ 2
E [ X n ˉ ] = μ V a r [ X n ˉ ] = 1 n σ 2 \mathrm{E}[\bar{X_n}]=\mu\\\mathrm{Var}[\bar{X_n}]=\frac{1}{n}\sigma^2 E [ X n ˉ ] = μ Var [ X n ˉ ] = n 1 σ 2
利用切比雪夫不等式,
1 − σ 2 n ϵ 2 ≤ P ( ∣ X n ˉ − μ ∣ < ϵ ) ≤ 1 1-\frac{\sigma^2}{n\epsilon^2}\leq P(|\bar{X_n}-\mu|<\epsilon)\leq1 1 − n ϵ 2 σ 2 ≤ P ( ∣ X n ˉ − μ ∣ < ϵ ) ≤ 1
n → ∞ n\rightarrow\infty n → ∞
P ( ∣ X n ˉ − μ ∣ < ϵ ) → 1 P(|\bar{X_n}-\mu|<\epsilon)\rightarrow1 P ( ∣ X n ˉ − μ ∣ < ϵ ) → 1
证毕.
证明是直接的,但是不是很令人满意,因为我们夹带了"V a r ( X k ) = σ 2 \mathrm{Var}(X_k)=\sigma^2 Var ( X k ) = σ 2
11.3 特征函数
特征函数及其性质
特征函数 是处理概率论问题的有力工具,它能:
将卷积运算化成乘法运算;
将求各阶矩的积分运算转化成微分运算;
将求随机变量序列的极限分布化成一般的函数极限问题;
方便地处理串级随机变量,应用于核辐射探测.
与之类似的概念还有矩母函数 和生成函数 .我们在这里专注于适用范围最广的特征函数 .
首先给个定义:
特征函数:
设X X X e i t X e^{itX} e i tX
ϕ ( t ) : = E ( e i t X ) , − ∞ < t < + ∞ \phi(t):=\mathrm{E}(e^{itX}),-\infty<t<+\infty ϕ ( t ) := E ( e i tX ) , − ∞ < t < + ∞
为随机变量X X X 特征函数 .
值得一提的是,由于∣ e i t X ∣ = 1 |e^{itX}|=1 ∣ e i tX ∣ = 1
为何要这么定义呢?我们把表达式写出来看看:
特征函数与傅里叶变换:
连续变量下,特征函数
ϕ ( t ) = ∫ − ∞ + ∞ e i t x f ( x ) d x \phi(t)=\int_{-\infty}^{+\infty}e^{itx}f(x)dx ϕ ( t ) = ∫ − ∞ + ∞ e i t x f ( x ) d x
是概率密度函数f ( x ) f(x) f ( x )
离散变量下,特征函数
ϕ ( t ) = ∑ k = 0 ∞ e i t x k p k \phi(t)=\sum_{k=0}^{\infty}e^{itx_k}p_k ϕ ( t ) = k = 0 ∑ ∞ e i t x k p k
仍然是一个连续函数.
我们看看特征函数的性质:
特征函数性质:
∣ ϕ ( t ) ∣ ≤ ϕ ( 0 ) = 1 |\phi(t)|\leq \phi(0)=1 ∣ ϕ ( t ) ∣ ≤ ϕ ( 0 ) = 1
ϕ ( − t ) = ϕ ∗ ( t ) \phi(-t)=\phi^*(t) ϕ ( − t ) = ϕ ∗ ( t )
ϕ a X + b ( t ) = e i b t ϕ X ( a t ) \phi_{aX+b}(t)=e^{ibt}\phi_X(at) ϕ a X + b ( t ) = e ib t ϕ X ( a t )
若随机变量X , Y X,Y X , Y ϕ X + Y ( t ) = ϕ X ( t ) ϕ Y ( t ) \phi_{X+Y}(t)=\phi_X(t)\phi_Y(t) ϕ X + Y ( t ) = ϕ X ( t ) ϕ Y ( t )
此即傅里叶变换中的卷积定理(卷积⟶ F \stackrel{\mathscr{F}}{\longrightarrow} ⟶ F
若E ( X l ) \mathrm{E}(X^l) E ( X l )
ϕ ( k ) ( 0 ) = i k E ( X k ) , 0 ≤ k ≤ l \phi^{(k)}(0)=i^k\mathrm{E}(X^k),0\leq k\leq l ϕ ( k ) ( 0 ) = i k E ( X k ) , 0 ≤ k ≤ l
因此,可以用特征函数的导数求随机变量的矩:E ( X k ) = ϕ ( k ) ( 0 ) i k \mathrm{E}(X^k)=\frac{\phi^{(k)}(0)}{i^k} E ( X k ) = i k ϕ ( k ) ( 0 )
一致 连续性:
∀ ϵ , ∃ δ , ∀ t ( ∣ ϕ ( t + δ ) − ϕ ( t ) ∣ < ϵ ) \forall\epsilon,\exists\delta,\forall t(|\phi(t+\delta)-\phi(t)|<\epsilon) ∀ ϵ , ∃ δ , ∀ t ( ∣ ϕ ( t + δ ) − ϕ ( t ) ∣ < ϵ )
注意,这比∀ t , ∀ ϵ , ∃ δ \forall t ,\forall \epsilon,\exists\delta ∀ t , ∀ ϵ , ∃ δ ∃ δ \exists \delta ∃ δ ∀ t \forall t ∀ t t t t
非负定性:
∀ z , t , [ ∑ i , j ϕ ( t i − t j ) z i z j ∗ ≥ 0 ] \forall \bm{z},\bm{t},\left[ \sum_{i,j}\phi(t_i-t_j)z_iz_j^*\geq 0 \right] ∀ z , t , [ i , j ∑ ϕ ( t i − t j ) z i z j ∗ ≥ 0 ]
唯一性:两变量若特征函数一致,则两函数也一致.
这由傅里叶变换的可逆性、唯一性保证(即{ e i t x } \{e^{itx}\} { e i t x } L 2 L^2 L 2
常见分布的特征函数
离散分布:
分布
概率分布P ( X = k ) P(X=k) P ( X = k )
特征函数ϕ ( t ) \phi(t) ϕ ( t )
01分布
p k ( 1 − p ) k , k = 0 , 1 p^k(1-p)^k,k=0,1 p k ( 1 − p ) k , k = 0 , 1 1 − p + p e i t \textcolor{blue}{1-p+pe^{it}} 1 − p + p e i t
b ( n , p ) b(n,p) b ( n , p ) ( n k ) p k ( 1 − p ) n − k , k = 0 , 1 , ⋯ , n \begin{pmatrix} n \\ k \end{pmatrix}p^k(1-p)^{n-k},k=0,1,\cdots,n ( n k ) p k ( 1 − p ) n − k , k = 0 , 1 , ⋯ , n ( 1 − p + p e i t ) n \textcolor{blue}{(1-p+pe^{it})^n} ( 1 − p + p e i t ) n
π ( λ ) \pi(\lambda) π ( λ ) ( λ k / k ! ) e − λ , k = 0 , 1 , 2 , ⋯ (\lambda^k/k!)e^{-\lambda},k=0,1,2,\cdots ( λ k / k !) e − λ , k = 0 , 1 , 2 , ⋯ e λ ( e i t − 1 ) \textcolor{blue}{e^{\lambda(e^{it}-1)}} e λ ( e i t − 1 )
G e ( p ) Ge(p) G e ( p ) ( 1 − p ) k − 1 p , k = 0 , 1 , ⋯ (1-p)^{k-1}p,k=0,1,\cdots ( 1 − p ) k − 1 p , k = 0 , 1 , ⋯ p 1 − q e i t , q : = 1 − p \textcolor{blue}{\frac{p}{1-qe^{it}},q:=1-p} 1 − q e i t p , q := 1 − p
连续分布:
分布
概率密度f ( x ) f(x) f ( x )
特征函数ϕ ( t ) \phi(t) ϕ ( t )
U ( a , b ) U(a,b) U ( a , b ) 1 / ( b − a ) , a < x < b 1/(b-a),a<x<b 1/ ( b − a ) , a < x < b e i b t − e i a t i t ( b − a ) \textcolor{blue}{\frac{e^{ibt}-e^{iat}}{it(b-a)}} i t ( b − a ) e ib t − e ia t
E x p ( λ ) Exp(\lambda) E x p ( λ ) λ e − λ x , x > 0 \lambda e^{-\lambda x},x>0 λ e − λ x , x > 0 ( 1 − i t / λ ) − 1 \textcolor{blue}{(1-it/\lambda)^{-1}} ( 1 − i t / λ ) − 1
N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) 1 2 π σ e − ( x − μ ) 2 2 σ 2 , − ∞ < x < + ∞ \frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}},-\infty<x<+\infty 2 π σ 1 e − 2 σ 2 ( x − μ ) 2 , − ∞ < x < + ∞ e i μ t − σ 2 t 2 2 \textcolor{blue}{e^{i\mu t-\frac{\sigma^2t^2}{2}}} e i μ t − 2 σ 2 t 2
G a ( α , λ ) Ga(\alpha,\lambda) G a ( α , λ ) λ α Γ ( α ) x α − 1 e − λ x , x ≥ 0 \frac{\lambda^\alpha}{\Gamma(\alpha)}x^{\alpha-1}e^{-\lambda x},x\geq 0 Γ ( α ) λ α x α − 1 e − λ x , x ≥ 0 ( 1 − i t / λ ) − α \textcolor{blue}{(1-it/\lambda)^{-\alpha}} ( 1 − i t / λ ) − α
χ 2 ( n ) \chi^2(n) χ 2 ( n ) x n / 2 − 1 2 n / 2 Γ ( n / 2 ) e − x / 2 , x > 0 \frac{x^{n/2-1}}{2^{n/2}\Gamma(n/2)}e^{-x/2},x>0 2 n /2 Γ ( n /2 ) x n /2 − 1 e − x /2 , x > 0 ( 1 − 2 i t ) − n / 2 \textcolor{blue}{(1-2it)^{-n/2}} ( 1 − 2 i t ) − n /2
B e ( a , b ) Be(a,b) B e ( a , b ) 1 B ( a , b ) x a − 1 ( 1 − x ) b − 1 , 0 < x < 1 \frac{1}{\Beta(a,b)}x^{a-1}(1-x)^{b-1},0<x<1 B ( a , b ) 1 x a − 1 ( 1 − x ) b − 1 , 0 < x < 1 a b ( a + b ) 2 ( a + b + 1 ) \textcolor{blue}{\frac{ab}{(a+b)^2(a+b+1)}} ( a + b ) 2 ( a + b + 1 ) ab
C a u ( μ , λ ) Cau(\mu,\lambda) C a u ( μ , λ ) 1 π 1 1 + x 2 , − ∞ < x < + ∞ \frac{1}{\pi}\frac{1}{1+x^2},-\infty<x<+\infty π 1 1 + x 2 1 , − ∞ < x < + ∞ e − ∣ t ∣ \textcolor{blue}{e^{-|t|}} e − ∣ t ∣
表格正确性自证.有了这些特征函数,结合其唯一性,我们可以证明之前不好证明的问题,比如:高斯分布相加还是高斯分布、计算高斯分布的期望和方差、二项分布的极限是泊松分布、卡方分布可以表征标准正态分布随机变量的平方和等.这些留作习题.
最后,我们考虑用它证明辛钦大数定律.
从特征函数到辛钦大数定律
辛钦大数定律证明2:
往证:
X n ˉ = 1 n ∑ i = 1 n X i → P , n → ∞ μ \bar{X_n}=\frac{1}{n}\sum_{i=1}^nX_i\stackrel{P,n\rightarrow\infty}{\rightarrow}\mu X n ˉ = n 1 i = 1 ∑ n X i → P , n → ∞ μ
左式对应的特征函数为ϕ X n ˉ ( t ) = [ ϕ X i ( t n ) ] n \phi_{\bar{X_n}}(t)=[\phi_{X_i}(\frac{t}{n})]^n ϕ X n ˉ ( t ) = [ ϕ X i ( n t ) ] n n → ∞ n\rightarrow\infty n → ∞
[ ϕ ( t n ) ] n = ( ϕ ( 0 ) + ϕ ′ ( 0 ) t n + o ( 1 n ) ) n = [ ϕ ( 0 ) ] n e x p [ n ln ( 1 + t ϕ ′ ( 0 ) ϕ ( 0 ) 1 n + o ( 1 / n ) ) ] → e i μ t \begin{aligned} \left[\phi(\frac{t}{n})\right]^n &= \left(\phi(0)+\phi'(0)\frac{t}{n}+o(\frac{1}{n})\right)^n\\ &= [\phi(0)]^n \mathrm{exp}\left[n\ln{\left(1+\frac{t\phi'(0)}{\phi(0)}\frac{1}{n}+o(1/n)\right)}\right]\\ &\rightarrow e^{i\mu t} \end{aligned} [ ϕ ( n t ) ] n = ( ϕ ( 0 ) + ϕ ′ ( 0 ) n t + o ( n 1 ) ) n = [ ϕ ( 0 ) ] n exp [ n ln ( 1 + ϕ ( 0 ) t ϕ ′ ( 0 ) n 1 + o ( 1/ n ) ) ] → e i μ t
以上利用了特征函数的性质.可见结果为随机变量μ \mu μ
证毕.
L12 中心极限定理
今天的证明仍然要用到特征函数,主要是以下三个:
几何分布G e ( p ) → ϕ ( t ) = p 1 − q e i t Ge(p)\rightarrow\phi(t)=\frac{p}{1-qe^{it}}
G e ( p ) → ϕ ( t ) = 1 − q e i t p
指数分布E x p ( λ ) → ϕ ( t ) = 1 1 − i t λ Exp(\lambda)\rightarrow\phi(t)=\frac{1}{1-\frac{it}{\lambda}}
E x p ( λ ) → ϕ ( t ) = 1 − λ i t 1
正态分布N ( μ , σ 2 ) → ϕ ( t ) = e i μ t − σ 2 t 2 2 N(\mu,\sigma^2)\rightarrow\phi(t)=e^{i\mu t-\frac{\sigma^2t^2}{2}}
N ( μ , σ 2 ) → ϕ ( t ) = e i μ t − 2 σ 2 t 2
什么是中心极限定理?可以追溯到Polya(Polya’s urn的那个):
Polya (1920)
It was generally known that the appearance of the Gaussian probability density e − x 2 e^{-x^2} e − x 2 a central role in probability theory.
简单来说,"中心极限定理"即在描述:什么情况下∑ i = 1 n X i \sum_{i=1}^{n}X_i ∑ i = 1 n X i
12.1 中心极限定理
先介绍教材上的版本:
中心极限定理 (Lindberg-Levi版本)
设随机变量序列X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X 1 , X 2 , ... , X n
E ( X k ) = μ , V a r ( X k ) = σ 2 > 0 , k = 1 , 2 , . . . , n \mathrm{E}(X_k)=\mu,\mathrm{Var}(X_k)=\sigma^2>0,k=1,2,...,n E ( X k ) = μ , Var ( X k ) = σ 2 > 0 , k = 1 , 2 , ... , n
则随机变量之和X : = ∑ i = 1 n X i X:=\sum_{i=1}^{n}X_i X := ∑ i = 1 n X i
Y n = X − E ( X ) V a r ( X ) = X − n μ n σ Y_n=\frac{X-\mathrm{E}(X)}{\sqrt{\mathrm{Var}(X)}}=\frac{X-n\mu}{\sqrt{n}\sigma} Y n = Var ( X ) X − E ( X ) = n σ X − n μ
的分布函数F n ( x ) F_n(x) F n ( x ) x x x
lim n → ∞ F n ( x ) = lim n → ∞ P ( X − n μ n σ ≤ x ) = ∫ − ∞ x 1 2 π e − t 2 2 d t = Φ ( x ) \lim_{n\rightarrow\infty}F_n(x)=\lim_{n\rightarrow\infty}P\left( \frac{X-n\mu}{\sqrt{n}\sigma}\leq x \right)=\int_{-\infty}^x \frac{1}{\sqrt{2\pi}}e^{-\frac{t^2}{2}}dt=\Phi(x) n → ∞ lim F n ( x ) = n → ∞ lim P ( n σ X − n μ ≤ x ) = ∫ − ∞ x 2 π 1 e − 2 t 2 d t = Φ ( x )
对上述定理的解读:
n n n Y n Y_n Y n 均值X ˉ ∼ N ( μ , σ 2 n ) , n → ∞ \bar{X}\sim N\left( \mu, \frac{\sigma^2}{n} \right),n\rightarrow\infty X ˉ ∼ N ( μ , n σ 2 ) , n → ∞
第二点是统计推断的基础 .
从中心极限定理看,为何许多的随机现象都服从正态分布?
彼此没有什么相依关系、对随机现象谁也不能起突出影响,而"均匀"地起到微小作用的随机因素共同作用叠加,结果呈现正态分布.
若描述此随机现象的随机变量为X X X X k X_k X k ∑ k X k \sum_kX_k ∑ k X k
例12.1 (DeMoivre-Laplace中心极限定理)
是最早的中心极限定理表述,可以看作Lindberg-Levi中心极限定理的二项分布特例,即假设Y n ∼ b ( n , p ) , 0 < p < 1 , n = 1 , 2 , . . . Y_n\sim b(n,p),0<p<1,n=1,2,... Y n ∼ b ( n , p ) , 0 < p < 1 , n = 1 , 2 , ...
Y n ∼ N [ n p , n p ( 1 − p ) ] , n → ∞ Y_n\sim N[np,np(1-p)],n\rightarrow\infty Y n ∼ N [ n p , n p ( 1 − p )] , n → ∞
例12.2 (良种数近似)
设一大批种子种良种占1/6.试估计在任选的6000粒种子中,良种比例与1/6比较上下小于1%的概率范围
解:
设X X X X ∼ b ( 6000 , 1 / 6 ) , E ( X ) = 1000 , V a r ( X ) = 5000 / 6 X\sim b(6000,1/6),\mathrm{E}(X)=1000,\mathrm{Var}(X)=5000/6 X ∼ b ( 6000 , 1/6 ) , E ( X ) = 1000 , Var ( X ) = 5000/6
I、切比雪夫不等式 (最粗糙)
P ( ∣ X − 1000 ∣ < 60 ) = 1 − P ( ∣ X − 1000 ∣ ≥ 60 ) ≥ 1 − 5000 / 6 6 0 2 = 0.7685 P(|X-1000|<60)=1-P(|X-1000|\geq 60)\geq 1-\frac{5000/6}{60^2}=0.7685 P ( ∣ X − 1000∣ < 60 ) = 1 − P ( ∣ X − 1000∣ ≥ 60 ) ≥ 1 − 6 0 2 5000/6 = 0.7685
II、中心极限定理
可近似认为X ∼ N ( 1000 , 5000 / 6 ) X\sim N(1000,5000/6) X ∼ N ( 1000 , 5000/6 )
P ( ∣ X − 1000 ∣ < 60 ) = 2 Φ ( 59 5000 / 6 ) − 1 = 0.9590287 P(|X-1000|<60)=2\Phi\left(\frac{59}{\sqrt{5000/6}}\right)-1=0.9590287 P ( ∣ X − 1000∣ < 60 ) = 2Φ ( 5000/6 59 ) − 1 = 0.9590287
如果在边界处取一个中间值,那么:
P ( ∣ X − 1000 ∣ < 60 ) = 2 Φ ( 59.5 5000 / 6 ) − 1 = 0.9607 P(|X-1000|<60)=2\Phi\left(\frac{59.5}{\sqrt{5000/6}}\right)-1=0.9607 P ( ∣ X − 1000∣ < 60 ) = 2Φ ( 5000/6 59.5 ) − 1 = 0.9607
III、二项分布精确值
P ( ∣ X − 1000 ∣ < 60 ) = P ( 940 < X < 1060 ) = ∑ k = 941 1059 ( 6000 k ) ( 1 / 6 ) k ( 5 / 6 ) 6000 − k = 0.9607 P(|X-1000|<60)=P(940<X<1060)=\sum_{k=941}^{1059}\begin{pmatrix} 6000\\k\end{pmatrix}(1/6)^k(5/6)^{6000-k}=0.9607 P ( ∣ X − 1000∣ < 60 ) = P ( 940 < X < 1060 ) = k = 941 ∑ 1059 ( 6000 k ) ( 1/6 ) k ( 5/6 ) 6000 − k = 0.9607
可见,中心极限定理在重复次数6000次后,已经是一个相当好的近似了,实际上n n n
从数学上看,高斯分布函数就是某函数不断自卷积所能达到的"天花板".
12.2 中心极限定理的证明
证明方法当然是使用我们强力的特征函数:
证明:
往证Levi版本:
Y n = ( ∑ i = 1 n X i ) − n μ n σ ⟶ P , n → ∞ Z ∼ N ( 0 , 1 ) Y_n=\frac{(\sum_{i=1}^nX_i)-n\mu}{\sqrt{n}\sigma}\stackrel{P,n\rightarrow\infty}{\longrightarrow}Z\sim N(0,1) Y n = n σ ( ∑ i = 1 n X i ) − n μ ⟶ P , n → ∞ Z ∼ N ( 0 , 1 )
RHS的特征函数ϕ Z ( t ) = e − t 2 2 \phi_Z(t)=e^{-\frac{t^2}{2}} ϕ Z ( t ) = e − 2 t 2
对LHS:
ϕ Y n ( t ) = [ ϕ X i − μ ( t n σ ) ] n = [ 1 + 1 2 ϕ X i − μ ′ ′ ( 0 ) ( t n σ ) 2 + o ( 1 n ) ] n = [ 1 + i 2 1 2 V a r ( X i ) ( t 2 n σ 2 ) + o ( 1 n ) ] n = n → ∞ e − t 2 2 = ϕ Z ( t ) \begin{aligned} \phi_{Y_n}(t)&=\left[ \phi_{X_i-\mu}\left( \frac{t}{\sqrt{n}\sigma} \right) \right]^n\\ &=\left[ 1+\frac{1}{2}\phi_{X_i-\mu}''(0)\left(\frac{t}{\sqrt{n}\sigma}\right)^2+o\left( \frac{1}{n}\right)\right]^n\\ &=\left[ 1+i^2\frac{1}{2}\mathrm{Var}(X_i)\left(\frac{t^2}{n\sigma^2}\right)+o\left( \frac{1}{n}\right)\right]^n \stackrel{n\rightarrow\infty}{=}e^{-\frac{t^2}{2}}=\phi_Z(t)\end{aligned} ϕ Y n ( t ) = [ ϕ X i − μ ( n σ t ) ] n = [ 1 + 2 1 ϕ X i − μ ′′ ( 0 ) ( n σ t ) 2 + o ( n 1 ) ] n = [ 1 + i 2 2 1 Var ( X i ) ( n σ 2 t 2 ) + o ( n 1 ) ] n = n → ∞ e − 2 t 2 = ϕ Z ( t )
用到了特征函数高阶导数与n n n
中心极限定理阐明了正态分布的来源:与二项分布、指数分布等由物理世界的性质决定不同,正态分布从极限起源.
中心极限定理诠释了正态分布的物理意义.
12.3 李雅普诺夫
独立同分布这个条件可能还是有点太强,现实世界中没有这么多独立同分布的情况,我们能不能把这个条件放开?
中心极限定理 (Lyapunov版本)
设随机变量序列X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X 1 , X 2 , ... , X n
E ( X k ) = μ k , V a r ( X k ) = σ k 2 > 0 , k = 1 , 2 , . . . , n \mathrm{E}(X_k)=\mu_k,\mathrm{Var}(X_k)=\sigma_k^2>0,k=1,2,...,n E ( X k ) = μ k , Var ( X k ) = σ k 2 > 0 , k = 1 , 2 , ... , n
记B n 2 = ∑ k = 1 n σ k 2 B_n^2=\sum_{k=1}^n\sigma_k^2 B n 2 = ∑ k = 1 n σ k 2 δ > 0 \delta>0 δ > 0 Lyapunov条件 :
lim n → ∞ 1 B n 2 + δ ∑ k = 1 n E ( ∣ X k − μ k ∣ 2 + δ ) = 0 \lim_{n\rightarrow\infty}\frac{1}{B_n^{2+\delta}}\sum_{k=1}^n\mathrm{E}(|X_k-\mu_k|^{2+\delta})=0 n → ∞ lim B n 2 + δ 1 k = 1 ∑ n E ( ∣ X k − μ k ∣ 2 + δ ) = 0
成立,则随机变量之和X : = ∑ k = 1 n X k X:=\sum_{k=1}^{n}X_k X := ∑ k = 1 n X k
Z n = X − ∑ i = 1 k μ k B n = X − n μ n σ Z_n=\frac{X-\sum_{i=1}^k\mu_k}{B_n}=\frac{X-n\mu}{\sqrt{n}\sigma} Z n = B n X − ∑ i = 1 k μ k = n σ X − n μ
的分布函数F n ( x ) F_n(x) F n ( x ) x x x
lim n → ∞ F n ( x ) = lim n → ∞ P ( X − ∑ i = 1 k μ k B n ≤ x ) = ∫ − ∞ x 1 2 π e − t 2 2 d t \lim_{n\rightarrow\infty}F_n(x)=\lim_{n\rightarrow\infty}P\left( \frac{X-\sum_{i=1}^k\mu_k}{B_n}\leq x \right)=\int_{-\infty}^x \frac{1}{\sqrt{2\pi}}e^{-\frac{t^2}{2}}dt n → ∞ lim F n ( x ) = n → ∞ lim P ( B n X − ∑ i = 1 k μ k ≤ x ) = ∫ − ∞ x 2 π 1 e − 2 t 2 d t
证明略.我们这不是数学课(笑).
Lyapunov版本的中心极限定理似乎更吓人了,但是大体思想与Lindberg-Levi版本的想法是类似的:它只是去掉了同分布假设,但又要求分布之间不那么不同 .以下为Lyapunov版本的一些要点:
当n n n Z n = X − ∑ i = 1 k μ k B n = X − n μ n σ Z_n=\frac{X-\sum_{i=1}^k\mu_k}{B_n}=\frac{X-n\mu}{\sqrt{n}\sigma} Z n = B n X − ∑ i = 1 k μ k = n σ X − n μ N ( 0 , 1 ) N(0,1) N ( 0 , 1 )
当n n n X = ∑ k = 1 n X k X=\sum_{k=1}^{n}X_k X = ∑ k = 1 n X k N ( ∑ k = 1 n μ k , B n 2 ) N(\sum_{k=1}^n\mu_k,B_n^2) N ( ∑ k = 1 n μ k , B n 2 )
也就是说,无论X k ( k = 1 , 2 , . . . ) X_k(k=1,2,...) X k ( k = 1 , 2 , ... ) n n n ∑ k = 1 n X k \sum_{k=1}^{n}X_k ∑ k = 1 n X k
上面看到,中心极限定理中,"同分布"这个条件是不重要的.下面我们会看到,甚至"独立"这个条件也不重要!
讲之前提一嘴:那什么条件重要?答案是:方差存在! .挺反直觉的,可以举个没有方差的粒子:
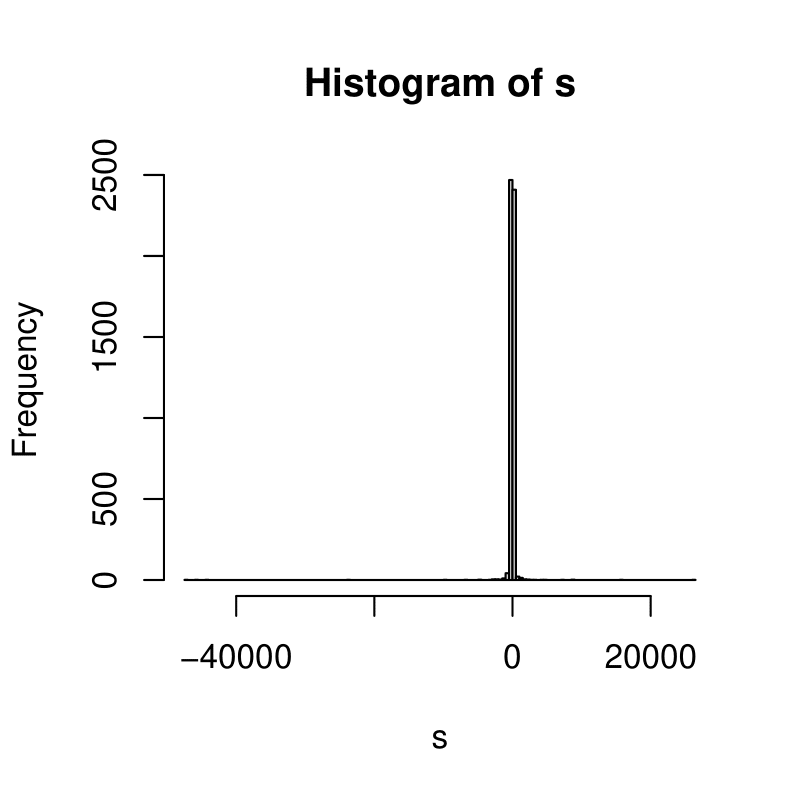
比如,20个独立同分布的柯西分布相加:
1 2 3 4 5 6 N <- 5000<- rep ( 0 , N) for ( i in 1 : 20 ) { <- s + rcauchy( N) } ( s, breaks= 200 )
结果是:
可以看到更像是Dirac delta而非正态分布的钟形曲线.
12.4 马尔可夫
马尔可夫是切比雪夫的学生,属于圣彼得堡学派,他反对莫斯科学派领袖Pavel Nekrasov提出的"大数定律的必要条件是被加的随机变量相互独立".因为直觉来讲,自然现象中有时间上的因果联系,因而被加项会有关联.
中心极限定理 (Markov版本)
设随机变量序列X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X 1 , X 2 , ... , X n
P ( X j ∣ X j − 1 , X j − 2 . . . ) = P ( X j ∣ X j − 1 ) P(X_j|X_{j-1},X_{j-2}...)=P(X_j|X_{j-1}) P ( X j ∣ X j − 1 , X j − 2 ... ) = P ( X j ∣ X j − 1 )
即具有马尔可夫性 .再加上可逆性、可达性条件,使其成为一个马尔科夫链 (在随机过程章节讨论).于是:
μ = E ( X 1 ) , σ 2 = V a r ( X 1 ) + 2 ∑ k = 1 ∞ C o v ( X 1 , X K + 1 ) < + ∞ ⟹ μ n : = 1 n ∑ k = 1 n X k ⟶ P , n → ∞ Z ∼ N ( μ , σ 2 n ) \mu=\mathrm{E}(X_1),\sigma^2=\mathrm{Var}(X_1)+2\sum_{k=1}^{\infty}\mathrm{Cov}(X_1,X_{K+1})<+\infty\\\Longrightarrow \mu_n:=\frac{1}{n}\sum_{k=1}^nX_k\stackrel{P,n\rightarrow\infty}{\longrightarrow}Z\sim N\left(\mu,\frac{\sigma^2}{n}\right) μ = E ( X 1 ) , σ 2 = Var ( X 1 ) + 2 k = 1 ∑ ∞ Cov ( X 1 , X K + 1 ) < + ∞ ⟹ μ n := n 1 k = 1 ∑ n X k ⟶ P , n → ∞ Z ∼ N ( μ , n σ 2 )
L13 蒙特卡洛方法
这一集没啥好讲的,值得一提的是蒙卡方法的几种种类吧:
之后统计学部分大概也不会记全篇笔记了,挑一点重难点记下来即可.
L13.5 指数分布族
指数分布族 指满足以下形式的密度函数/分布列:
f ( x ∣ θ ) = h ( x ) e x p [ ∑ i = 1 s η i ( θ ) T i ( x ) − A ( η ) ] f(x|\bm{\theta})=h(x)\mathrm{exp}\left[ \sum_{i=1}^s\eta_i(\bm{\theta})T_i(x)-A(\bm{\eta}) \right]
f ( x ∣ θ ) = h ( x ) exp [ i = 1 ∑ s η i ( θ ) T i ( x ) − A ( η ) ]
s s s 维数 .
其标准形式是以η \bm{\eta} η θ \bm{\theta} θ η : = ( η 1 , η 2 , . . . , η s ) ⊤ , T ( x ) : = ( T 1 ( x ) , T 2 ( x ) , . . . , T s ( x ) ) \bm{\eta}:=(\eta_1,\eta_2,...,\eta_s)^\top,\bm{T}(x):=(T_1(x),T_2(x),...,T_s(x)) η := ( η 1 , η 2 , ... , η s ) ⊤ , T ( x ) := ( T 1 ( x ) , T 2 ( x ) , ... , T s ( x ))
f ( x ∣ η ) = h ( x ) e x p [ η ⊤ T ( x ) − A ( η ) ] f(x|\bm{\eta})=h(x)\mathrm{exp}\left[ \bm{\eta}^\top \bm{T}(x)-A(\bm{\eta}) \right]
f ( x ∣ η ) = h ( x ) exp [ η ⊤ T ( x ) − A ( η ) ]
仔细看就会发现,我们熟悉的许多分布都是指数分布族的一员:
本讲主要关注了指数分布族在求期望、方差 时的共性.下面开始推导,不妨假设为连续型随机变量,积分默认对实数范围(事实上离散型的求和号和这里的积分号并没有什么大不同,毕竟我们用到的唯一性质就是交换偏导与积分/求和,这里都可以满足.):
注意到,作为随机变量密度函数的f ( x ∣ η ) f(x|\bm{\eta}) f ( x ∣ η )
∫ f ( x ∣ η ) d x = 1 \int f(x|\bm{\eta})dx=1
∫ f ( x ∣ η ) d x = 1
代入标准形式我们有一个关键推论:
e x p [ A ( η ) ] = ∫ h ( x ) e x p [ η ⊤ T ( x ) ] d x \mathrm{exp}[A(\bm{\eta})]=\int h(x)\mathrm{exp}\left[ \bm{\eta}^\top \bm{T}(x)\right ]dx
exp [ A ( η )] = ∫ h ( x ) exp [ η ⊤ T ( x ) ] d x
一些notation:∂ A ∂ η = ( ∂ A ∂ η 1 , ∂ A ∂ η 2 , . . . , ∂ A ∂ η s ) , ∂ 2 A ∂ η 2 = ( ∂ 2 A ∂ η 1 2 , ∂ 2 A ∂ η 2 2 , . . . , ∂ 2 A ∂ η s 2 ) \frac{\partial A}{\partial \bm{\eta}}=(\frac{\partial A}{\partial \eta_1},\frac{\partial A}{\partial \eta_2},...,\frac{\partial A}{\partial \eta_s}),\frac{\partial^2 A}{\partial \bm{\eta}^2}=(\frac{\partial^2 A}{\partial \eta_1^2},\frac{\partial^2 A}{\partial \eta_2^2},...,\frac{\partial^2 A}{\partial \eta_s^2}) ∂ η ∂ A = ( ∂ η 1 ∂ A , ∂ η 2 ∂ A , ... , ∂ η s ∂ A ) , ∂ η 2 ∂ 2 A = ( ∂ η 1 2 ∂ 2 A , ∂ η 2 2 ∂ 2 A , ... , ∂ η s 2 ∂ 2 A )
我们对着关键推论求导一次即可得到:
∂ A ∂ η e x p [ A ( η ) ] = ∫ h ( x ) e x p [ η ⊤ T ( x ) ] T ( x ) d x \frac{\partial A}{\partial \bm{\eta}}\mathrm{exp}[A(\bm{\eta})]=\int h(x)\mathrm{exp}\left[ \bm{\eta}^\top \bm{T}(x)\right ]\bm{T}(x)dx
∂ η ∂ A exp [ A ( η )] = ∫ h ( x ) exp [ η ⊤ T ( x ) ] T ( x ) d x
进而有:
∂ A ∂ η = ∫ h ( x ) e x p [ η ⊤ T ( x ) − A ( η ) ] T ( x ) d x = ∫ f ( x ∣ η ) T ( x ) d x = E ( T ( x ) ) \begin{aligned}
\frac{\partial A}{\partial \bm{\eta}}&=\int h(x)\mathrm{exp}\left[ \bm{\eta}^\top \bm{T}(x)-A(\bm{\eta}) \right ]\bm{T}(x)dx\\
&=\int f(x|\bm{\eta})\bm{T}(x)dx\\
&=\mathrm{E}(\bm{T}(x))
\end{aligned}
∂ η ∂ A = ∫ h ( x ) exp [ η ⊤ T ( x ) − A ( η ) ] T ( x ) d x = ∫ f ( x ∣ η ) T ( x ) d x = E ( T ( x ))
求导两次即可得到:
[ ∂ 2 A ∂ η 2 + ( ∂ A ∂ η ) 2 ] e x p [ A ( η ) ] = ∫ h ( x ) e x p [ η ⊤ T ( x ) ] T 2 ( x ) d x \left[\frac{\partial^2 A}{\partial \bm{\eta}^2}+\left( \frac{\partial A}{\partial \bm{\eta}} \right)^2\right]\mathrm{exp}[A(\bm{\eta})]=\int h(x)\mathrm{exp}\left[ \bm{\eta}^\top \bm{T}(x)\right ]\bm{T^2}(x)dx
[ ∂ η 2 ∂ 2 A + ( ∂ η ∂ A ) 2 ] exp [ A ( η )] = ∫ h ( x ) exp [ η ⊤ T ( x ) ] T 2 ( x ) d x
进而有:
∂ 2 A ∂ η 2 = E ( T 2 ( x ) ) − ( ∂ A ∂ η ) 2 = V a r ( T ( x ) ) \begin{aligned}
\frac{\partial^2 A}{\partial \bm{\eta}^2}&=\mathrm{E}(\bm{T^2}(x))-\left( \frac{\partial A}{\partial \bm{\eta}} \right)^2\\
&=\mathrm{Var}(\bm{T}(x))
\end{aligned}
∂ η 2 ∂ 2 A = E ( T 2 ( x )) − ( ∂ η ∂ A ) 2 = Var ( T ( x ))
也就是说,标准形式指数分布族(或其内蕴函数)的方差、期望可以用下式求解:
V a r ( T ( x ) ) = ∂ 2 A ∂ η 2 , E ( T ( x ) ) = ∂ A ∂ η \mathrm{Var}(\bm{T}(x))=\frac{\partial^2 A}{\partial \bm{\eta}^2},\,\,\,\,\,\mathrm{E}(\bm{T}(x))=\frac{\partial A}{\partial \bm{\eta}}
Var ( T ( x )) = ∂ η 2 ∂ 2 A , E ( T ( x )) = ∂ η ∂ A
特别地,当s = 1 , T ( x ) = x s=1,T(x)=x s = 1 , T ( x ) = x
M f ( t ) = E ( e t X ) = exp [ A ( η + t ) − A ( η ) ] C f ( t ) = ln ( M f ( t ) ) = A ( η + t ) − A ( η ) M_f(t)=\mathrm{E}(e^{tX})=\exp[A(\eta+t)-A(\eta)]\\
C_f(t)=\ln(M_f(t))=A(\eta+t)-A(\eta)
M f ( t ) = E ( e tX ) = exp [ A ( η + t ) − A ( η )] C f ( t ) = ln ( M f ( t )) = A ( η + t ) − A ( η )
证明略,代入不难.
作为练习,可以利用指数分布族的性质求一下分布形式的期望、方差:
泊松分布π ( λ ) \pi(\lambda) π ( λ )
二项分布b ( n , p ) b(n,p) b ( n , p ) θ \bm{\theta} θ
正态分布N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 )
伽马分布G a ( α , λ ) Ga(\alpha,\lambda) G a ( α , λ )
L14 统计学概论
统计学 是收集、分析、表述(图表)、解释数据的科学.它包罗万象,甚至可以说,它包含了所有的实证科学.
统计学的七大准则:
Aggregation 概括(削减信息以让人获得更多信息,less is more)
Information Measurement 信息度量(根号n准则,数据越多,新数据的信息量越少)
Likelihood 似然与概率论
Intercomparison 完备性(统计学有一套自洽的数据分析体系,可以独立于具体的实证科学领域工作)
Regression 回归
Design 实验设计
Residual 分析已知与未知(残差分析?)
统计学分两大块:描述统计学 与推断统计学 .
对描述统计学 (descriptive statistics),我们希望以直观的图表展示数据的基本信息,以:
常用的图表有:
分布表(频数、频率)
直方图(频数、频率、频数密度、频率密度四种)
箱线图
可以用R语言绘图(核心制图系统、ggplot系统)
对推断统计学 ,我们希望对已取得的观测值进行整理、分析,作出推断、决策,从而找出所研究的对象的规律性.它是用样本数据对总体的某些特征进行估计和检验的统计学.
内容:参数估计;假设检验
目的:对总体(一个随机变量)特征作出判断
L15 统计量与分布
15.1 随机样本
总体 X X X 随机变量 .我们在统计学里更多说"总体".它有三层含义:
个体 是组成总体的每一个元素,可以看作随机变量X X X X i X_i X i
样本 是从总体中抽取的部分个体.
用( X 1 , X 2 , ⋯ , X n ) (X_1,X_2,\cdots,X_n) ( X 1 , X 2 , ⋯ , X n ) n n n
用( x 1 , x 2 , ⋯ , x n ) (x_1,x_2,\cdots,x_n) ( x 1 , x 2 , ⋯ , x n ) X X X n n n 样本观测值 .
样本空间 即样本所有可能取值的集合.
学概率论的时候也有"样本空间",它和统计学里的样本空间是否等价呢?这里我们认为它们就是一回事.
若总体X X X ( X 1 , X 2 , ⋯ , X n ) (X_1,X_2,\cdots,X_n) ( X 1 , X 2 , ⋯ , X n ) 独立同分布(i.i.d) ,则称其为简单随机样本 .
关于样本的抽样方法:
对有限总体,放回抽样可以得到简单随机样本;
如果放回抽样不方便,常常用不放回抽样代替,条件:N / n ≥ 10 N/n \geq 10 N / n ≥ 10 N N N n n n
15.2 统计量
统计量 即样本的不含未知参数 的连续函数g ( X 1 , X 2 , ⋯ , X n ) g(X_1,X_2,\cdots,X_n) g ( X 1 , X 2 , ⋯ , X n )
利用样本的函数——统计量——进行统计推断;
样本是随机变量,故统计量也是随机变量.
例15.1
考虑1 σ 2 ∑ i = 1 n ( X i − μ ) 2 \frac{1}{\sigma^2}\sum_{i=1}^{n}(X_i-\mu)^2 σ 2 1 ∑ i = 1 n ( X i − μ ) 2 μ , σ 2 \mu,\sigma^2 μ , σ 2
常见统计量:
样本均值:X ˉ = 1 n ∑ i = 1 n X i \bar{X}=\frac{1}{n}\sum_{i=1}^nX_i X ˉ = n 1 ∑ i = 1 n X i
样本方差:S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ˉ ) 2 S^2=\frac{1}{n-1}\sum_{i=1}^n(X_i-\bar{X})^2 S 2 = n − 1 1 ∑ i = 1 n ( X i − X ˉ ) 2 n − 1 n-1 n − 1
样本标准差:S 2 \sqrt{S^2} S 2
样本k k k A k = 1 n ∑ i = 1 n X i k A_k=\frac{1}{n}\sum_{i=1}^nX_i^k A k = n 1 ∑ i = 1 n X i k A 1 = X ˉ A_1=\bar{X} A 1 = X ˉ
样本k k k B k = 1 n ∑ i = 1 n ( X i − X ˉ ) k B_k=\frac{1}{n}\sum_{i=1}^n(X_i-\bar{X})^k B k = n 1 ∑ i = 1 n ( X i − X ˉ ) k B 2 = n − 1 n S 2 : = S n 2 B_2=\frac{n-1}{n}S^2:=S_n^2 B 2 = n n − 1 S 2 := S n 2
样本均值的性质:
(一阶性质):偏差 定义为样本中数据与样本均值之差,则样本所有偏差之和为0,即:
∑ i = 1 n ( X i − X ˉ ) = 0 \sum_{i=1}^n(X_i-\bar{X})=0
i = 1 ∑ n ( X i − X ˉ ) = 0
(二阶性质):数据观察值与样本均值的偏差平方和最小,也就是说,形如∑ i = 1 n ( X i − c ) 2 \sum_{i=1}^n(X_i-c)^2 ∑ i = 1 n ( X i − c ) 2 c = X ˉ c=\bar{X} c = X ˉ
以及回顾一下中心极限定理的统计学结果:
中心极限定理:
设X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X 1 , X 2 , ⋯ , X n X ˉ \bar{X} X ˉ
若总体分布为N ( μ , σ 2 ) N(\mu,\sigma^2) N ( μ , σ 2 ) X ˉ ∼ N ( μ , σ 2 n ) \bar{X}\sim N(\mu,\frac{\sigma^2}{n}) X ˉ ∼ N ( μ , n σ 2 ) 若总体分布未知/不是正态分布,但E ( X ) = μ , V a r ( X ) = σ 2 \mathrm{E}(X)=\mu,\mathrm{Var}(X)=\sigma^2 E ( X ) = μ , Var ( X ) = σ 2 n n n X ˉ \bar{X} X ˉ N ( μ , σ 2 n ) N(\mu,\frac{\sigma^2}{n}) N ( μ , n σ 2 )
这样我们就获得了样本一二阶矩的性质:
一二阶矩性质:
设总体X X X E ( X ) = μ , V a r ( X ) = σ 2 < + ∞ \mathrm{E}(X)=\mu,\mathrm{Var}(X)=\sigma^2<+\infty E ( X ) = μ , Var ( X ) = σ 2 < + ∞ X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X 1 , X 2 , ⋯ , X n X ˉ , S 2 \bar{X},S^2 X ˉ , S 2
E ( X ˉ ) = μ V a r ( X ˉ ) = σ 2 n E ( S 2 ) = σ 2 \mathrm{E}(\bar{X})=\mu\\\mathrm{Var}(\bar{X})=\frac{\sigma^2}{n}\\\mathrm{E}(S^2)=\sigma^2 E ( X ˉ ) = μ Var ( X ˉ ) = n σ 2 E ( S 2 ) = σ 2
注意区别:样本方差S 2 S^2 S 2 σ 2 : = V a r ( X ) \sigma^2:=\mathrm{Var}(X) σ 2 := Var ( X )
解:
对第三式,考虑样本二阶中心矩:
S n 2 = B 2 = 1 n ∑ i = 1 n ( X i − X ˉ ) 2 = 1 n ( ∑ i = 1 n X i 2 − 2 X ˉ ∑ i = 1 n X i + n X ˉ 2 ) = 1 n ∑ i = 1 n X i 2 − X ˉ 2 \begin{aligned} S_n^2=B^2&=\frac{1}{n}\sum_{i=1}^n(X_i-\bar{X})^2\\ &=\frac{1}{n}\left( \sum_{i=1}^nX_i^2 -2\bar{X}\sum_{i=1}^nX_i +n\bar{X}^2 \right)\\ &=\frac{1}{n}\sum_{i=1}^nX_i^2-\bar{X}^2\end{aligned} S n 2 = B 2 = n 1 i = 1 ∑ n ( X i − X ˉ ) 2 = n 1 ( i = 1 ∑ n X i 2 − 2 X ˉ i = 1 ∑ n X i + n X ˉ 2 ) = n 1 i = 1 ∑ n X i 2 − X ˉ 2
这一过程和概率论中算随机变量的方差很像,只不过我们这里算出来的结果还是一个随机变量,而非一个数.于是:
E ( S n 2 ) = E ( 1 n ∑ i = 1 n X i 2 ) − E ( X ˉ 2 ) = n n [ V a r ( X ) + E 2 ( X ) ] − [ V a r ( X ˉ ) + E 2 ( X ˉ ) ] = ( σ 2 + μ 2 ) − ( 1 n σ 2 + μ 2 ) = n − 1 n σ 2 \begin{aligned} \mathrm{E}(S_n^2)&=\mathrm{E}\left(\frac{1}{n}\sum_{i=1}^nX_i^2\right)-\mathrm{E}(\bar{X}^2)\\ &=\frac{n}{n}[\mathrm{Var}(X)+\mathrm{E}^2(X)]-[\mathrm{Var}(\bar{X})+\mathrm{E}^2(\bar{X})]\\ &=(\sigma^2+\mu^2)-\left( \frac{1}{n}\sigma^2+\mu^2\right)\\ &=\frac{n-1}{n}\sigma^2\end{aligned} E ( S n 2 ) = E ( n 1 i = 1 ∑ n X i 2 ) − E ( X ˉ 2 ) = n n [ Var ( X ) + E 2 ( X )] − [ Var ( X ˉ ) + E 2 ( X ˉ )] = ( σ 2 + μ 2 ) − ( n 1 σ 2 + μ 2 ) = n n − 1 σ 2
所以S 2 : = n n − 1 S n 2 = 1 n − 1 ∑ i = 1 n ( X i − X ˉ ) 2 = σ 2 S^2:=\frac{n}{n-1}S_n^2=\frac{1}{n-1}\sum_{i=1}^n(X_i-\bar{X})^2=\sigma^2 S 2 := n − 1 n S n 2 = n − 1 1 ∑ i = 1 n ( X i − X ˉ ) 2 = σ 2
15.3 统计量的分布
统计量既然是仅依赖于样本的随机变量,它也应该由概率分布,T n = g ( X 1 , X 2 , ⋯ , X n ) T_n=g(X_1,X_2,\cdots,X_n) T n = g ( X 1 , X 2 , ⋯ , X n ) 抽样分布
例15.2(正态分布总体的样本均值)
设总体X ∼ N ( μ , σ 2 ) X\sim N(\mu,\sigma^2) X ∼ N ( μ , σ 2 ) ( X 1 , X 2 , ⋯ , X n ) (X_1,X_2,\cdots,X_n) ( X 1 , X 2 , ⋯ , X n )
X ˉ ∼ N ( μ , σ 2 n ) \bar{X}\sim N\left( \mu,\frac{\sigma^2}{n} \right) X ˉ ∼ N ( μ , n σ 2 )
正态分布是最简单的情况,接下来要介绍更复杂的情况:
χ 2 \chi^2 χ 2 先回忆一下概率论中涉及的卡方分布相关性质:
我们证明过:若X ∼ N ( 0 , 1 ) X\sim N(0,1) X ∼ N ( 0 , 1 ) X 2 ∼ χ 2 ( 1 ) = G a ( 1 / 2 , 1 / 2 ) X^2\sim \chi^2(1)=Ga(1/2,1/2) X 2 ∼ χ 2 ( 1 ) = G a ( 1/2 , 1/2 )
我们还证明过:伽马分布的α \alpha α
伽马分布:
G a ( α , λ ) : f ( x ; α , λ ) = λ α Γ ( α ) x α − 1 e − λ x Ga(\alpha,\lambda):f(x;\alpha,\lambda)=\frac{\lambda^\alpha}{\Gamma(\alpha)}x^{\alpha-1}e^{-\lambda x}
G a ( α , λ ) : f ( x ; α , λ ) = Γ ( α ) λ α x α − 1 e − λ x
于是:
卡方分布(χ 2 \chi^2 χ 2
设X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X 1 , X 2 , ⋯ , X n N ( 0 , 1 ) N(0,1) N ( 0 , 1 )
∑ i = 1 n X i 2 ∼ χ 2 ( n ) \sum_{i=1}^nX_i^2\sim \chi^2(n) i = 1 ∑ n X i 2 ∼ χ 2 ( n )
其中n n n
χ 2 ( n ) \chi^2(n) χ 2 ( n )
f χ 2 ( n ) ( x ) = ( 1 / 2 ) n / 2 Γ ( n / 2 ) x n / 2 − 1 e − x / 2 , x ∈ ( 0 , + ∞ ) f_{\chi^2(n)}(x)=\frac{(1/2)^{n/2}}{\Gamma(n/2)}x^{n/2-1}e^{-x/2},x\in(0,+\infty) f χ 2 ( n ) ( x ) = Γ ( n /2 ) ( 1/2 ) n /2 x n /2 − 1 e − x /2 , x ∈ ( 0 , + ∞ )
可见χ 2 ( n ) = G a ( n / 2 , 1 / 2 ) \chi^2(n)=Ga(n/2,1/2) χ 2 ( n ) = G a ( n /2 , 1/2 )
卡方分布性质:
对X ∼ χ 2 ( n ) X\sim \chi^2(n) X ∼ χ 2 ( n ) E ( X ) = n , V a r ( X ) = 2 n \mathrm{E}(X)=n,\mathrm{Var}(X)=2n E ( X ) = n , Var ( X ) = 2 n
若X 1 ∼ χ 2 ( n 1 ) , X 2 ∼ χ 2 ( n 2 ) X_1\sim \chi^2(n_1),X_2\sim \chi^2(n_2) X 1 ∼ χ 2 ( n 1 ) , X 2 ∼ χ 2 ( n 2 ) X 1 , X 2 X_1,X_2 X 1 , X 2 X 1 + X 2 ∼ χ 2 ( n 1 + n 2 ) X_1+X_2\sim \chi^2(n_1+n_2) X 1 + X 2 ∼ χ 2 ( n 1 + n 2 )
随着自由度n n n χ 2 \chi^2 χ 2
注意性质一用到了:X ∼ G a ( α , λ ) ⇒ V a r ( X ) = α / λ 2 X\sim Ga(\alpha,\lambda)\Rightarrow \mathrm{Var}(X)=\alpha/\lambda^2 X ∼ G a ( α , λ ) ⇒ Var ( X ) = α / λ 2
接下来引入上α \alpha α 的概念(如果不说"上",默认为下分位点):
上α \alpha α z α z_\alpha z α
设X X X 0 < α < 1 0<\alpha<1 0 < α < 1 P ( X > z α ) = α P(X>z_\alpha)=\alpha P ( X > z α ) = α z α z_\alpha z α X X X 上α \alpha α .
对卡方分布,上述写法一般改成:P { χ 2 > χ α 2 ( n ) } = ∫ χ α 2 ( n ) ∞ f χ 2 ( n ) ( y ) d y = α P\{\chi^2>\chi_\alpha^2(n)\}=\int_{\chi^2_\alpha(n)}^\infty f_{\chi^2(n)}(y)dy=\alpha P { χ 2 > χ α 2 ( n )} = ∫ χ α 2 ( n ) ∞ f χ 2 ( n ) ( y ) d y = α
为何卡方分布更关心上分位数?这是因为卡方分布定义域有下界,而无上界.两边都无界的分布常用双侧分位数,我们马上就会看到示例.
卡方分布常见于描述正态总体样本方差的分布,例如:当总体X ∼ N ( μ , σ 2 ) X\sim N(\mu,\sigma^2) X ∼ N ( μ , σ 2 ) σ 2 \sigma^2 σ 2 ( X 1 , X 2 , ⋯ , X n ) (X_1,X_2,\cdots,X_n) ( X 1 , X 2 , ⋯ , X n )
( n − 1 ) S 2 σ 2 = ∑ i = 1 n ( X i − X ˉ σ ) ∼ χ 2 ( n − 1 ) \frac{(n-1)S^2}{\sigma^2}=\sum_{i=1}^n\left(\frac{X_i-\bar{X}}{\sigma}\right)\sim \chi^2(n-1)
σ 2 ( n − 1 ) S 2 = i = 1 ∑ n ( σ X i − X ˉ ) ∼ χ 2 ( n − 1 )
这一式子的证明比较繁杂,但是结论非常重要,毕竟如果把样本均值换成总体均值,我们有:
∑ i = 1 n ( X i − μ σ ) ∼ χ 2 ( n ) \sum_{i=1}^n\left(\frac{X_i-\mu}{\sigma}\right)\sim \chi^2(n)
i = 1 ∑ n ( σ X i − μ ) ∼ χ 2 ( n )
可见用样本均值估计时,得到的卡方分布自由度少了1.
F分布
F分布基于卡方分布构造而来:
F分布
设随机变量X ∼ χ 2 ( n ) , Y ∼ χ 2 ( m ) X\sim\chi^2(n),Y\sim\chi^2(m) X ∼ χ 2 ( n ) , Y ∼ χ 2 ( m ) X , Y X,Y X , Y
F = X / n Y / m F=\frac{X/n}{Y/m} F = Y / m X / n
称F F F n n n m m m
F分布的概率密度为:
f F ( x ) = Γ ( m + n 2 ) ( n m ) n / 2 Γ ( m 2 ) Γ ( n 2 ) x n 2 − 1 ( 1 + n m x ) − m + n 2 , x ∈ ( 0 , + ∞ ) f_F(x)=\frac{\Gamma(\frac{m+n}{2})(\frac{n}{m})^{n/2}}{\Gamma(\frac{m}{2})\Gamma(\frac{n}{2})}x^{\frac{n}{2}-1}\left(1+\frac{n}{m}x\right)^{-\frac{m+n}{2}},x\in (0,+\infty) f F ( x ) = Γ ( 2 m ) Γ ( 2 n ) Γ ( 2 m + n ) ( m n ) n /2 x 2 n − 1 ( 1 + m n x ) − 2 m + n , x ∈ ( 0 , + ∞ )
F分布得名于Ronald.A.Fisher(1890-1962)的首字母,其概率密度函数的推导要领为:
考察Z = X Y Z=\frac{X}{Y} Z = Y X
乘以系数F = m n Z F=\frac{m}{n}Z F = n m Z
在之后的假设检验中,F分布将会很有用.
F分布性质:
若F ∼ F ( n , m ) F\sim F(n,m) F ∼ F ( n , m ) 1 F ∼ F ( n , m ) \frac{1}{F}\sim F(n,m) F 1 ∼ F ( n , m )
F 1 − α ( n , m ) = 1 F α ( m , n ) F_{1-\alpha}(n,m)=\frac{1}{F_\alpha(m,n)} F 1 − α ( n , m ) = F α ( m , n ) 1 F α ( n , m ) F_\alpha(n,m) F α ( n , m ) F ( n , m ) F(n,m) F ( n , m ) α \alpha α
性质2的推导:对于X ∼ F ( n , m ) X\sim F(n,m) X ∼ F ( n , m ) Y = 1 X Y=\frac{1}{X} Y = X 1
P ( X > F 1 − α ( n , m ) ) = 1 − α ⇒ P ( Y < 1 F 1 − α ( n , m ) ) = 1 − α ⇒ P ( Y > 1 F 1 − α ( n , m ) ) = α \begin{aligned}
&P(X>F_{1-\alpha}(n,m))=1-\alpha\\
\Rightarrow&P\left(Y<\frac{1}{F_{1-\alpha}(n,m)}\right)=1-\alpha\\
\Rightarrow&P\left(Y>\frac{1}{F_{1-\alpha}(n,m)}\right)=\alpha
\end{aligned} ⇒ ⇒ P ( X > F 1 − α ( n , m )) = 1 − α P ( Y < F 1 − α ( n , m ) 1 ) = 1 − α P ( Y > F 1 − α ( n , m ) 1 ) = α
由性质1知,Y ∼ F ( m , n ) Y\sim F(m,n) Y ∼ F ( m , n ) F α ( m , n ) = 1 F 1 − α ( n , m ) F_\alpha(m,n)=\frac{1}{F_{1-\alpha}(n,m)} F α ( m , n ) = F 1 − α ( n , m ) 1
F分布常见于两个正态总体的比较,接卡方分布中的总体X X X X ′ ∼ N ( μ ′ , σ ′ 2 ) X'\sim N(\mu',\sigma'^2) X ′ ∼ N ( μ ′ , σ ′2 ) ( X 1 ′ , X 2 ′ , ⋯ , X n ′ ′ ) (X_1',X_2',\cdots,X_{n'}') ( X 1 ′ , X 2 ′ , ⋯ , X n ′ ′ ) ( X 1 , X 2 , ⋯ , X n ) (X_1,X_2,\cdots,X_n) ( X 1 , X 2 , ⋯ , X n )
S 2 / S ′ 2 σ 2 / σ ′ 2 ∼ F ( n − 1 , n ′ − 1 ) \frac{S^2/S'^2}{\sigma^2/\sigma'^2}\sim F(n-1,n'-1)
σ 2 / σ ′2 S 2 / S ′2 ∼ F ( n − 1 , n ′ − 1 )
t分布
t分布
设随机变量X ∼ N ( 0 , 1 ) , Y ∼ χ 2 ( n ) X\sim N(0,1),Y\sim\chi^2(n) X ∼ N ( 0 , 1 ) , Y ∼ χ 2 ( n ) X , Y X,Y X , Y
T = X Y / n T=\frac{X}{\sqrt{Y/n}} T = Y / n X
称T T T n n n
t分布的概率密度为:
f T ( x ) = t f T 2 ( t 2 ) = Γ ( n + 1 2 ) Γ ( n 2 ) n π ( 1 + t 2 n ) − n + 1 2 , t ∈ R f_T(x)=tf_{T^2}(t^2)=\frac{\Gamma(\frac{n+1}{2})}{\Gamma(\frac{n}{2})\sqrt{n\pi}}\left(1+\frac{t^2}{n}\right)^{-\frac{n+1}{2}},t\in \mathbb{R} f T ( x ) = t f T 2 ( t 2 ) = Γ ( 2 n ) nπ Γ ( 2 n + 1 ) ( 1 + n t 2 ) − 2 n + 1 , t ∈ R
t分布概率密度推导要领为:
T 2 = X 2 / 1 Y 2 / n T^2=\frac{X^2/1}{Y^2/n} T 2 = Y 2 / n X 2 /1 T 2 ∼ F ( 1 , n ) T^2\sim F(1,n) T 2 ∼ F ( 1 , n ) T = T 2 T=\sqrt{T^2} T = T 2
t分布性质:
f n ( t ) f_n(t) f n ( t )
n → ∞ , f n ( t ) → ϕ ( t ) = 1 2 π e − x 2 2 n\rightarrow\infty,f_n(t)\rightarrow\phi(t)=\frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}} n → ∞ , f n ( t ) → ϕ ( t ) = 2 π 1 e − 2 x 2
t分布的上α \alpha α t α t_\alpha t α P ( T > t α ) = α P(T>t_\alpha)=\alpha P ( T > t α ) = α − t α = t 1 − α -t_\alpha=t_{1-\alpha} − t α = t 1 − α
t分布的双侧α \alpha α t α / 2 t_{\alpha/2} t α /2 P ( ∣ T ∣ > t α / 2 ) = α P(|T|>t_{\alpha/2})=\alpha P ( ∣ T ∣ > t α /2 ) = α α / 2 \alpha/2 α /2
t分布常见于用样本方差标准化样本均值的分布.设总体X ∼ N ( μ , σ 2 ) X\sim N(\mu,\sigma^2) X ∼ N ( μ , σ 2 ) μ \mu μ ( X 1 , X 2 , ⋯ , X n ) (X_1,X_2,\cdots,X_n) ( X 1 , X 2 , ⋯ , X n )
X ˉ − μ S / n ∼ t ( n − 1 ) \frac{\bar{X}-\mu}{S/\sqrt{n}}\sim t(n-1)
S / n X ˉ − μ ∼ t ( n − 1 )
L16 点估计
16.1 统计推断
统计推断是数理统计理论的重要部分,建立在概率论的基础上.目的是利用从总体抽出的样本,推断总体的性质(期望,方差,分布等).具体来讲,即以下步骤:
X → 采样 X n → g 统计量 X\stackrel{采样}{\rightarrow}X_n\stackrel{g}{\rightarrow}统计量
X → 采样 X n → g 统计量
其中,随机变量函数g g g
统计推断的基本问题是:
首先讨论参数估计问题:
参数 θ \theta θ μ , σ 2 \mu,\sigma^2 μ , σ 2 当该数量未知时,从总体抽出一个样本,用一定方法对它参数估计 .
方法问题:如何利用样本估计位置参数?
评判标准:如何评价估计的好坏?
其中,点估计 估计未知参数的值;区间估计 估计未知参数的取值范围,并使此范围包含参数真值的概率为给定的值(“置信度”).
16.2 点估计
例16.1
设在炸药制造厂,一天中发生着火的次数X X X λ \lambda λ λ \lambda λ
着火次数k k k 0 1 2 3 4 5 6 7 发生k k k n k n_k n k 75 90 54 22 6 2 1 0 ∑ = 250 \sum=250 ∑ = 250
解:
由于X ∼ π ( λ ) X\sim \pi(\lambda) X ∼ π ( λ ) λ = E ( X ) \lambda=\mathrm{E}(X) λ = E ( X ) E ( X ) \mathrm{E}(X) E ( X ) 大数定律 ),由数据计算得到X ˉ = 1.22 \bar{X}=1.22 X ˉ = 1.22
λ ^ = 1.22 \hat{\lambda}=1.22 λ ^ = 1.22
如果用样本方差估计,由于λ = V a r ( X ) \lambda=\mathrm{Var}(X) λ = Var ( X ) s 2 = 1.27 s^2=1.27 s 2 = 1.27
λ ^ = 1.27 \hat{\lambda}=1.27 λ ^ = 1.27
1.27和1.22很接近,一方面在一定程度上说明,最初对总体满足泊松分布的假设 是合理的;但是两者毕竟不一样,哪个估计更好呢?
以上例题其实就是一个点估计的过程,下面为点估计下定义:
点估计:
用一个数值作为位置参数的估计值称为点估计 .
设总体X X X θ \theta θ X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X 1 , X 2 , ⋯ , X n
点估计构造一个适当的统计量θ ^ ( X 1 , X 2 , ⋯ , X n ) \hat{\theta}(X_1,X_2,\cdots,X_n) θ ^ ( X 1 , X 2 , ⋯ , X n ) θ ^ ( x 1 , x 2 , ⋯ , x n ) \hat{\theta}(x_1,x_2,\cdots,x_n) θ ^ ( x 1 , x 2 , ⋯ , x n )
约定:“尖帽符号^ \hat{} ^
点估计确定参数的准则有很多种,这节课先介绍常用的三种:矩估计,最大似然估计,最小二乘估计.
16.3 矩估计法
对总体的k k k X k ˉ \bar{X^k} X k ˉ E ( X k ) \mathrm{E}(X^k) E ( X k )
矩估计:
用样本的k k k k k k
设随机变量X ∼ f ( x ; θ 1 , θ 2 , ⋯ , θ k ) X\sim f(x;\theta_1,\theta_2,\cdots,\theta_k) X ∼ f ( x ; θ 1 , θ 2 , ⋯ , θ k ) θ 1 , θ 2 , ⋯ , θ k \theta_1,\theta_2,\cdots,\theta_k θ 1 , θ 2 , ⋯ , θ k k k k
E ( X r ) = μ r ( θ 1 , θ 2 , ⋯ , θ k ) , 1 ≤ r ≤ k \mathrm{E}(X^r)=\mu_r(\theta_1,\theta_2,\cdots,\theta_k),1\leq r\leq k E ( X r ) = μ r ( θ 1 , θ 2 , ⋯ , θ k ) , 1 ≤ r ≤ k
设X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X 1 , X 2 , ⋯ , X n X X X r r r
A r ≡ X r ˉ = 1 n ∑ i = 1 n X i r A_r\equiv \bar{X^r}=\frac{1}{n}\sum_{i=1}^nX_i^r A r ≡ X r ˉ = n 1 i = 1 ∑ n X i r
A r A_r A r
用样本矩作为对应总体矩的估计量; 用样本矩的函数作为对应总体矩函数的估计量. 总体的前k k k k k k
μ i = μ i ( θ 1 , θ 2 , ⋯ , θ k ) , 1 ≤ i ≤ k \mu_i=\mu_i(\theta_1,\theta_2,\cdots,\theta_k),1\leq i \leq k μ i = μ i ( θ 1 , θ 2 , ⋯ , θ k ) , 1 ≤ i ≤ k
一般情况下,可以用上述方程反解出参数:
θ i = θ i ( μ 1 , μ 2 , ⋯ , μ k ) , 1 ≤ i ≤ k \theta_i=\theta_i(\mu_1,\mu_2,\cdots,\mu_k),1\leq i \leq k θ i = θ i ( μ 1 , μ 2 , ⋯ , μ k ) , 1 ≤ i ≤ k
用样本矩A r A_r A r μ r , 1 ≤ r ≤ k \mu_r,1\leq r \leq k μ r , 1 ≤ r ≤ k 矩估计量 :
θ i ^ = θ i ^ ( A 1 , A 2 , ⋯ , A k ) , 1 ≤ i ≤ k \hat{\theta_i}=\hat{\theta_i}(A_1,A_2,\cdots,A_k),1\leq i \leq k θ i ^ = θ i ^ ( A 1 , A 2 , ⋯ , A k ) , 1 ≤ i ≤ k
矩估计量的观察值称为矩估计值 .
一般将上述矩估计用矢量表示:前k k k A = ( A 1 , A 2 , ⋯ , A k ) \bm{A}=(A_1,A_2,\cdots,A_k) A = ( A 1 , A 2 , ⋯ , A k ) θ = ( θ 1 , θ 2 , ⋯ , θ k ) \bm{\theta}=(\theta_1,\theta_2,\cdots,\theta_k) θ = ( θ 1 , θ 2 , ⋯ , θ k ) X = ( X 1 , X 2 , ⋯ , X n ) \bm{X}=(X_1,X_2,\cdots,X_n) X = ( X 1 , X 2 , ⋯ , X n ) k k k μ ( θ ) = ( μ 1 ( θ ) , μ 2 ( θ ) , ⋯ , μ k ( θ ) ) \bm{\mu}(\bm{\theta})=(\mu_1(\bm{\theta}),\mu_2(\bm{\theta}),\cdots,\mu_k(\bm{\theta})) μ ( θ ) = ( μ 1 ( θ ) , μ 2 ( θ ) , ⋯ , μ k ( θ ))
因此,在例16.1中,如果我们用矩估计法做点估计,应当采用样本1阶矩来估计λ \lambda λ
矩估计中,取样本矩的数量k k k 待估参数的数量 ,并且应当尽量取前k k k ,原因是阶数越小,估计效果越好.这一点会在下一堂课介绍.
例16.2
设总体X ∼ E x p ( λ ) X\sim \mathrm{Exp}(\lambda) X ∼ Exp ( λ ) f ( x ) = λ e − λ x f(x)=\lambda e^{-\lambda x} f ( x ) = λ e − λ x X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X 1 , X 2 , ⋯ , X n λ \lambda λ
解:
总体的一阶矩:
μ 1 = E ( X ) = 1 λ \mu_1=\mathrm{E}(X)=\frac{1}{\lambda} μ 1 = E ( X ) = λ 1
反解得到:
λ = 1 μ 1 \lambda=\frac{1}{\mu_1} λ = μ 1 1
于是参数的矩估计为:
λ ^ = 1 A 1 = 1 X ˉ \hat{\lambda}=\frac{1}{A_1}=\frac{1}{\bar{X}} λ ^ = A 1 1 = X ˉ 1
例16.3
证明:若总体的期望μ \mu μ σ 2 \sigma^2 σ 2
μ ^ = X ˉ σ 2 ^ = n − 1 n S 2 = S n 2 \hat{\mu}=\bar{X}\\\hat{\sigma^2}=\frac{n-1}{n}S^2=S_n^2 μ ^ = X ˉ σ 2 ^ = n n − 1 S 2 = S n 2
解:
总体的前2阶矩:
{ μ 1 = E ( X ) = μ μ 2 = E ( X 2 ) = V a r ( X ) + E 2 ( X ) = σ 2 + μ 2 \begin{cases} \mu_1=\mathrm{E}(X)=\mu\\ \mu_2=\mathrm{E}(X^2)=\mathrm{Var}(X)+\mathrm{E}^2(X)=\sigma^2+\mu^2\end{cases} { μ 1 = E ( X ) = μ μ 2 = E ( X 2 ) = Var ( X ) + E 2 ( X ) = σ 2 + μ 2
反解得到:
{ μ = μ 1 σ 2 = μ 2 − μ 1 2 \begin{cases} \mu=\mu_1\\ \sigma^2=\mu_2-\mu_1^2\end{cases} { μ = μ 1 σ 2 = μ 2 − μ 1 2
用样本矩代替总体矩即得到对应矩估计.
例16.3
设总体X ∼ U ( a , b ) X\sim U(a,b) X ∼ U ( a , b ) X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X 1 , X 2 , ... , X n a , b a,b a , b
解:
可验证矩估计量为:
{ a ^ = A 1 − 3 ( A 2 − A 1 2 ) = A 1 − 3 B 2 b ^ = A 1 + 3 ( A 2 − A 1 2 ) = A 1 + 3 B 2 \begin{cases} \hat{a}=A_1-\sqrt{3(A_2-A_1^2)}=A_1-\sqrt{3B_2}\\ \hat{b}=A_1+\sqrt{3(A_2-A_1^2)}=A_1+\sqrt{3B_2}\end{cases} { a ^ = A 1 − 3 ( A 2 − A 1 2 ) = A 1 − 3 B 2 b ^ = A 1 + 3 ( A 2 − A 1 2 ) = A 1 + 3 B 2
16.4 最大似然估计法
直觉告诉我们,一次试验就出现的事件有较大的概率.譬如,现有两个箱子,各放100个球.一个箱子里99个红球,1个白球;另一个箱子里1个红球,99个白球.现从某个箱子中拿出一个球,结果取得白球,那么是从哪个箱子里取的球呢?显然,更可能是从那个99个白球的箱子里取的球.
类似的,对于手头的样本,我们可以考虑连续变换待求参数θ \bm{\theta} θ
最大似然估计:
用得到对应样本观测值的概率作为待求参数的似然函数 ,通过求似然函数的最大值来解出对应的参数估计值.
定义似然函数 L ( x , θ ) L(\bm{x},\bm{\theta}) L ( x , θ )
对离散型随机变量X X X P ( X = x ) = p ( x , θ ) , x = u 1 , u 2 , . . . , θ ∈ Θ P(X=x)=p(x,\theta),x=u_1,u_2,...,\bm{\theta}\in\Theta P ( X = x ) = p ( x , θ ) , x = u 1 , u 2 , ... , θ ∈ Θ X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X 1 , X 2 , ⋯ , X n L ( x , θ ) = P ( X 1 = x 1 , X 2 = x 2 , . . . , X n = x n ) = ∏ i = 1 n p ( x i , θ ) L(\bm{x},\bm{\theta})=P(X_1=x_1,X_2=x_2,...,X_n=x_n)=\prod_{i=1}^np(x_i,\bm{\theta}) L ( x , θ ) = P ( X 1 = x 1 , X 2 = x 2 , ... , X n = x n ) = i = 1 ∏ n p ( x i , θ )
对连续型随机变量X X X f ( x , θ ) f(x,\bm{\theta}) f ( x , θ ) L ( x , θ ) = ∏ i = 1 n f ( x i , θ ) L(\bm{x},\bm{\theta})=\prod_{i=1}^nf(x_i,\bm{\theta}) L ( x , θ ) = i = 1 ∏ n f ( x i , θ )
最大似然法(Maximum Likelihood Estimation,MLE) :
θ ^ ( x ) = arg max L ( x ; θ ) \hat{\bm{\theta}}(\bm{x})=\argmax{L(\bm{x};\bm{\theta})} θ ^ ( x ) = arg max L ( x ; θ )
称为参数θ \bm{\theta} θ 最大似然估计值 ,称统计量θ ^ = θ ^ ( X ) \hat{\bm{\theta}}=\hat{\bm{\theta}}(\bm{X}) θ ^ = θ ^ ( X ) θ \bm{\theta} θ 最大似然估计量 .
若L ( x , θ ) L(\bm{x},\bm{\theta}) L ( x , θ ) θ \bm{\theta} θ
∂ ∂ θ r L ( x , θ ) = 0 , r = 1 , 2 , . . . , k \frac{\partial}{\partial \theta_r}L(\bm{x},\bm{\theta})=0,r=1,2,...,k ∂ θ r ∂ L ( x , θ ) = 0 , r = 1 , 2 , ... , k
为似然方程组 ,∂ ∂ θ r log L = 0 \frac{\partial}{\partial \theta_r}\log L=0 ∂ θ r ∂ log L = 0 对数似然方程组 .arg max L \argmax L arg max L
例16.4
设总体X X X P ( X = 1 ) = p P(X=1)=p P ( X = 1 ) = p p p p
解:
设x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x 1 , x 2 , ... , x n X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X 1 , X 2 , ... , X n
P ( X 1 = x 1 , X 2 = x 2 , . . . , X n = x n ) = ∏ i = 1 n P ( X i = x i ) = p ∑ i = 1 n x i ( 1 − p ) n − ∑ i = 1 n x i ≡ L ( p ) P(X_1=x_1,X_2=x_2,...,X_n=x_n)=\prod_{i=1}^nP(X_i=x_i)=p^{\sum_{i=1}^nx_i}(1-p)^{n-\sum_{i=1}^nx_i}\equiv L(p) P ( X 1 = x 1 , X 2 = x 2 , ... , X n = x n ) = i = 1 ∏ n P ( X i = x i ) = p ∑ i = 1 n x i ( 1 − p ) n − ∑ i = 1 n x i ≡ L ( p )
对不同的p p p L ( p ) L(p) L ( p ) L ( p ) L(p) L ( p )
p ^ = arg max L ( p ) \hat{p}=\argmax{L(p)} p ^ = arg max L ( p )
又,由于log \log log
p ^ = arg max log L ( p ) \hat{p}=\argmax{\log{L(p)}} p ^ = arg max log L ( p )
于是:
d d p log L ( p ) ∣ p = p ^ = ∑ i = 1 n x i p ^ − n − ∑ i = 1 n x i 1 − p ^ = 0 ⟹ p ^ = 1 n ∑ i = 1 n x i = x ˉ \left.\frac{d}{dp}\log{L(p)}\right|_{p=\hat{p}}=\frac{\sum_{i=1}^nx_i}{\hat{p}}-\frac{n-\sum_{i=1}^nx_i}{1-\hat{p}}=0\\\Longrightarrow \hat{p}=\frac{1}{n}\sum_{i=1}^nx_i=\bar{x} d p d log L ( p ) p = p ^ = p ^ ∑ i = 1 n x i − 1 − p ^ n − ∑ i = 1 n x i = 0 ⟹ p ^ = n 1 i = 1 ∑ n x i = x ˉ
所以,p ^ = x ˉ \hat{p}=\bar{x} p ^ = x ˉ p p p
例16.5
设总体X ∼ N ( μ , σ 2 ) X\sim N(\mu,\sigma^2) X ∼ N ( μ , σ 2 ) X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X 1 , X 2 , ... , X n μ , σ 2 \mu,\sigma^2 μ , σ 2
解:
可以求得:
{ μ ^ = x ˉ σ 2 ^ = x 2 ˉ − ( x ˉ ) 2 \begin{cases} \hat{\mu}=\bar{x}\\ \hat{\sigma^2}=\bar{x^2}-(\bar{x})^2\end{cases} { μ ^ = x ˉ σ 2 ^ = x 2 ˉ − ( x ˉ ) 2
结果和矩估计一样.
例16.6
设总体X ∼ U ( a , b ) X\sim U(a,b) X ∼ U ( a , b ) X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X 1 , X 2 , ... , X n a , b a,b a , b
解:
似然函数:
L ( a , b ) = { 1 ( b − a ) n , a ≤ min x i ≤ max x i ≤ b 0 , 其他 L(a,b)=\begin{cases} \frac{1}{(b-a)^n},&a\leq \min{x_i}\leq\max{x_i}\leq b\\ 0,&其他\end{cases} L ( a , b ) = { ( b − a ) n 1 , 0 , a ≤ min x i ≤ max x i ≤ b 其他
当a = min x i , b = max x i a=\min{x_i},b=\max{x_i} a = min x i , b = max x i L ( a , b ) L(a,b) L ( a , b )
a ^ = min X i , b ^ = max X i \hat{a}=\min{X_i},\hat{b}=\max{X_i} a ^ = min X i , b ^ = max X i
该结果和矩估计不一样!
16.5 最小二乘估计
历史悠久;
计算高效;
估计量是样本的线性组合,复杂性可控;
本节课不展开,在线性回归中进一步讨论.
L17 点估计的评价
回忆点估计:构造统计量θ ^ ( X 1 , X 2 , . . . , X n ) \hat{\theta}(X_1,X_2,...,X_n) θ ^ ( X 1 , X 2 , ... , X n ) 估计量的选择(构造) ,这一构造的好坏即对于点估计的评价.
17.1 评价标准
对于同一个未知参数,不同方法得到的估计量可能不同,于是提问:
应该选哪种估计量?
用什么标准评价一个估计量的好坏?
预告:标准与数字特征紧密相关:
无偏性 —数学期望有效性 —方差相合性 —依概率收敛
17.2 相合性
相合性(consistency) ,又称一致性
相合性
设θ ^ ( X 1 , X 2 , . . . , X n ) \hat{\theta}(X_1,X_2,...,X_n) θ ^ ( X 1 , X 2 , ... , X n ) θ \theta θ
∀ θ ∈ Θ ( θ ^ ⟶ P θ ) \forall \theta \in \Theta(\hat{\theta}\stackrel{P}{\longrightarrow}\theta) ∀ θ ∈ Θ ( θ ^ ⟶ P θ )
则称θ ^ \hat{\theta} θ ^ θ \theta θ 相合估计量 .
这里由于θ ^ \hat{\theta} θ ^ n n n θ ^ n \hat{\theta}_n θ ^ n θ ^ n ⟶ P θ \hat{\theta}_n\stackrel{P}{\longrightarrow}\theta θ ^ n ⟶ P θ 基本要求 .如果相合性不符合,即使样本容量n n n
相合性判定的原始判定(依概率收敛)涉及概率取极限,比较复杂,这里有利用期望和方差的简化版本(前提:两者均存在).这一定理利用了:我们所期望收敛的随机变量θ \theta θ
定理(相合性判定)
设θ ^ ( X 1 , X 2 , . . . , X n ) \hat{\theta}(X_1,X_2,...,X_n) θ ^ ( X 1 , X 2 , ... , X n ) θ \theta θ
lim n → ∞ E ( θ ^ n ) = θ , lim n → ∞ V a r ( θ ^ n ) = 0 \lim_{n\rightarrow \infty}\mathrm{E}(\hat{\theta}_n)=\theta,\lim_{n\rightarrow\infty}\mathrm{Var}(\hat{\theta}_n)=0 n → ∞ lim E ( θ ^ n ) = θ , n → ∞ lim Var ( θ ^ n ) = 0
则θ ^ \hat{\theta} θ ^ θ \theta θ
这两个条件看上去还是不够紧凑,我们可以定义均方误差(mean-square error,MSE) ,把这两者合二为一
其实灵感来源就是:( x − a ) 2 + ( y − b ) 2 = 0 ⇔ x = a , y = b (x-a)^2+(y-b)^2=0 \Leftrightarrow x=a,y=b ( x − a ) 2 + ( y − b ) 2 = 0 ⇔ x = a , y = b
均方误差(mean-square error,MSE)
M S E ( θ ^ n ) ≡ E [ ( θ ^ n − θ ) 2 ] = V a r ( θ ^ n ) + [ E ( θ ^ n ) − θ ] 2 \mathrm{MSE}(\hat{\theta}_n)\equiv \mathrm{E}[(\hat{\theta}_n-\theta)^2]=\mathrm{Var}(\hat{\theta}_n)+[\mathrm{E}(\hat{\theta}_n)-\theta]^2 MSE ( θ ^ n ) ≡ E [( θ ^ n − θ ) 2 ] = Var ( θ ^ n ) + [ E ( θ ^ n ) − θ ] 2
于是相合性判定的定理条件可以写成:
lim n → ∞ M S E ( θ ^ n ) = 0 \lim_{n\rightarrow\infty}\mathrm{MSE}(\hat{\theta}_n)=0 n → ∞ lim MSE ( θ ^ n ) = 0
类似地,相合估计量的函数也对应具有相合性:
函数的相合性
若θ ^ 1 n , θ ^ 2 n , . . . , θ ^ k n \hat{\theta}_{1n},\hat{\theta}_{2n},...,\hat{\theta}_{kn} θ ^ 1 n , θ ^ 2 n , ... , θ ^ kn θ 1 , θ 2 , . . . , θ k \theta_1,\theta_2,...,\theta_k θ 1 , θ 2 , ... , θ k η = g ( θ 1 , θ 2 , . . . , θ k ) \eta=g(\theta_1,\theta_2,...,\theta_k) η = g ( θ 1 , θ 2 , ... , θ k ) η ^ = g ( θ ^ 1 n , θ ^ 2 n , . . . , θ ^ k n ) \hat{\eta}=g(\hat{\theta}_{1n},\hat{\theta}_{2n},...,\hat{\theta}_{kn}) η ^ = g ( θ ^ 1 n , θ ^ 2 n , ... , θ ^ kn ) η \eta η
例17.1
设X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X 1 , X 2 , ... , X n X ∼ U ( 0 , θ ) X\sim U(0,\theta) X ∼ U ( 0 , θ ) θ \theta θ
解:
上一节中证明了,θ \theta θ θ ^ n = max ( X 1 , X 2 , . . . , X n ) \hat{\theta}_n=\max(X_1,X_2,...,X_n) θ ^ n = max ( X 1 , X 2 , ... , X n ) F θ ^ n ( x ) F_{\hat{\theta}_n}(x) F θ ^ n ( x )
F θ ^ n ( x ) = ( x θ ) n I ( 0 < x < θ ) F_{\hat{\theta}_n}(x)=\left(\frac{x}{\theta}\right)^nI(0<x<\theta) F θ ^ n ( x ) = ( θ x ) n I ( 0 < x < θ )
则概率密度函数为
f θ ^ n ( x ) = n θ ( x θ ) n − 1 I ( 0 < x < θ ) f_{\hat{\theta}_n}(x)=\frac{n}{\theta}\left(\frac{x}{\theta}\right)^{n-1}I(0<x<\theta) f θ ^ n ( x ) = θ n ( θ x ) n − 1 I ( 0 < x < θ )
于是容易算出
E ( θ ^ n ) = ∫ x f θ ^ n ( x ) d x = n n + 1 θ V a r ( θ ^ n ) = ∫ ( x − E ( θ ^ n ) ) 2 f θ ^ n ( x ) d x = n ( n + 2 ) ( n + 1 ) 2 θ 2 \mathrm{E}(\hat{\theta}_n)=\int xf_{\hat{\theta}_n}(x)dx=\frac{n}{n+1}\theta\\\mathrm{Var}(\hat{\theta}_n)=\int (x-\mathrm{E}(\hat{\theta}_n))^2f_{\hat{\theta}_n}(x)dx=\frac{n}{(n+2)(n+1)^2}\theta^2 E ( θ ^ n ) = ∫ x f θ ^ n ( x ) d x = n + 1 n θ Var ( θ ^ n ) = ∫ ( x − E ( θ ^ n ) ) 2 f θ ^ n ( x ) d x = ( n + 2 ) ( n + 1 ) 2 n θ 2
容易验证
lim n → ∞ E ( θ ^ n ) = θ , lim n → ∞ V a r ( θ ^ n ) = 0 \lim_{n\rightarrow \infty}\mathrm{E}(\hat{\theta}_n)=\theta,\lim_{n\rightarrow\infty}\mathrm{Var}(\hat{\theta}_n)=0 n → ∞ lim E ( θ ^ n ) = θ , n → ∞ lim Var ( θ ^ n ) = 0
即θ ^ n \hat{\theta}_n θ ^ n θ \theta θ
17.3 无偏性
无偏性
称θ ^ \hat{\theta} θ ^ θ \theta θ 无偏估计量 ,若
E ( θ ^ ) ≡ θ \mathrm{E}(\hat{\theta})\equiv\theta E ( θ ^ ) ≡ θ
对比相合性的定义,可见无偏性对于期望的要求比起相合性要更进一步,即要求无论样本容量n n n
样本均值X ˉ \bar{X} X ˉ E ( X ) \mathrm{E}(X) E ( X )
样本二阶原点矩A 2 = 1 n ∑ i = 1 n X i 2 A_2=\frac{1}{n}\sum_{i=1}^nX_i^2 A 2 = n 1 ∑ i = 1 n X i 2 μ 2 = E ( X 2 ) \mu_2=\mathrm{E}(X^2) μ 2 = E ( X 2 )
S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ˉ ) 2 S^2=\frac{1}{n-1}\sum_{i=1}^n(X_i-\bar{X})^2 S 2 = n − 1 1 ∑ i = 1 n ( X i − X ˉ ) 2 V a r ( X ) \mathrm{Var}(X) Var ( X )
S n 2 = n − 1 n S 2 S_n^2=\frac{n-1}{n}S^2 S n 2 = n n − 1 S 2 V a r ( X ) \mathrm{Var}(X) Var ( X ) 渐进无偏估计量 .
目前已经引入了"相合",“无偏”,"渐进无偏"三个概念,它们之间的推断关系是微妙的:
仅有渐进无偏性不能推出相合性.17.2中的相合性判定定理,实际上说的就是:
渐进无偏估计 + 方差趋于零 → 相合估计 渐进无偏估计+方差趋于零→相合估计
渐进无偏估计 + 方差趋于零 → 相合估计
无偏只对期望做要求,因而不能推出相合(反例:考虑分布为"双峰型"的无偏估计,它的方差并不趋于0,因而不相合)
只有期望存在,相合才可以推出渐进无偏(即相合性判定定理的逆定理)
可见,相合性与无偏性两者描述的范围有交集,但也有彼此的侧重点,没有包含关系.
例17.2
设X 1 , X 2 , . . . , X m X_1,X_2,...,X_m X 1 , X 2 , ... , X m X ∼ U ( n , p ) X\sim U(n,p) X ∼ U ( n , p ) n > 1 n>1 n > 1 p 2 p^2 p 2
解:
样本的前二阶矩为
A 1 ≡ E ( X ˉ ) = n p A 2 ≡ E ( 1 m ∑ i = 1 m X i 2 ) = E ( X 2 ) = ( n 2 − n ) p 2 + n p A_1\equiv\mathrm{E}(\bar{X})=np\\A_2\equiv\mathrm{E}\left(\frac{1}{m}\sum_{i=1}^mX_i^2\right)=\mathrm{E}(X^2)=(n^2-n)p^2+np A 1 ≡ E ( X ˉ ) = n p A 2 ≡ E ( m 1 i = 1 ∑ m X i 2 ) = E ( X 2 ) = ( n 2 − n ) p 2 + n p
于是
p 2 = 1 n 2 − n [ E ( 1 m ∑ i = 1 m X i 2 ) − E ( X ˉ ) ] = E [ 1 ( n 2 − n ) m ∑ i = 1 m X i ( X i − 1 ) ] \begin{aligned} p^2 &=\frac{1}{n^2-n}\left[\mathrm{E}\left(\frac{1}{m}\sum_{i=1}^mX_i^2\right)-\mathrm{E}(\bar{X})\right]\\ &=\mathrm{E}\left[\frac{1}{(n^2-n)m}\sum_{i=1}^mX_i(X_i-1)\right]\end{aligned} p 2 = n 2 − n 1 [ E ( m 1 i = 1 ∑ m X i 2 ) − E ( X ˉ ) ] = E [ ( n 2 − n ) m 1 i = 1 ∑ m X i ( X i − 1 ) ]
也就是说,p 2 p^2 p 2
p 2 ^ = 1 ( n 2 − n ) m ∑ i = 1 m X i ( X i − 1 ) \hat{p^2}=\frac{1}{(n^2-n)m}\sum_{i=1}^mX_i(X_i-1) p 2 ^ = ( n 2 − n ) m 1 i = 1 ∑ m X i ( X i − 1 )
17.4 有效性
有效性
设θ ^ 1 ( X 1 , X 2 , . . . , X n ) , θ ^ 2 ( X 1 , X 2 , . . . , X n ) \hat{\theta}_1(X_1,X_2,...,X_n),\hat{\theta}_2(X_1,X_2,...,X_n) θ ^ 1 ( X 1 , X 2 , ... , X n ) , θ ^ 2 ( X 1 , X 2 , ... , X n ) θ \theta θ 无偏估计量 ,且V a r ( θ ^ 1 ) < V a r ( θ ^ 2 ) \mathrm{Var}(\hat{\theta}_1)<\mathrm{Var}(\hat{\theta}_2) Var ( θ ^ 1 ) < Var ( θ ^ 2 ) θ ^ 1 \hat{\theta}_1 θ ^ 1 θ ^ 2 \hat{\theta}_2 θ ^ 2 有效 .
一致最小方差无偏估计(UMVUE)
如果一个估计量比任何其他估计量都有效,则称之为一致最小方差无偏估计(uniformly minimum variance unbiased estimator,UMVUE)
有趣的是,关于无偏估计的方差下界确有定理:
定理(Cramer-Rao下限) L ( X ; θ ) L(X;\theta) L ( X ; θ ) θ \theta θ X X X θ \theta θ θ ^ n \hat{\theta}_n θ ^ n
V a r ( θ ^ n ) ≥ 1 n E ( ∂ log L ( X ; θ ) ∂ θ ) \mathrm{Var}(\hat{\theta}_n)\geq \frac{1}{n\mathrm{E}\left(\frac{\partial \log{L(X;\theta)}}{\partial\theta}\right)} Var ( θ ^ n ) ≥ n E ( ∂ θ ∂ l o g L ( X ; θ ) ) 1
达到Cramer-Rao理论极限的估计量称为有效估计量 .
以下结论是最大似然估计量 应用的理论支撑,证明较难,不做细致讨论了.
例17.3
设X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X 1 , X 2 , ... , X n μ , σ 2 \mu,\sigma^2 μ , σ 2 μ \mu μ \hat{\mu}_1\equivX_1,\hat{\mu}_2\equiv\bar{X} ,哪个估计量更有效?
解:
容易发现两者均无偏,而
V a r ( μ ^ 1 ) = σ 2 , V a r ( μ ^ 2 ) = σ 2 n \mathrm{Var}(\hat{\mu}_1)=\sigma^2,\mathrm{Var}(\hat{\mu}_2)=\frac{\sigma^2}{n} Var ( μ ^ 1 ) = σ 2 , Var ( μ ^ 2 ) = n σ 2
n > 1 n>1 n > 1 V a r ( μ ^ 1 ) > V a r ( μ ^ 2 ) \mathrm{Var}(\hat{\mu}_1)>\mathrm{Var}(\hat{\mu}_2) Var ( μ ^ 1 ) > Var ( μ ^ 2 ) μ ^ 2 \hat{\mu}_2 μ ^ 2
上例给我们的启示:
用全部数据的平均估计总体均值要比只使用部分数据更有效;
数据积累,估计量的方差越来越小,参数越来越精确,相应地信息量 越来越大.
17.5 例:最小二乘估计
**最小二乘估计法(Least Square Method,LSE)**是自古以来最广泛采用的参数估计法之一,源于天文学和测地学的应用.
当总体分布的函数形式并不严格知道,无法进行最大似然估计时,运用最小二乘法往往十分方便.
由Gauss和Legendre在同一时代发现.
假设某个随机变量Y Y Y X X X θ \theta θ
Y = f ( X ; θ ) Y=f(X;\theta)
Y = f ( X ; θ )
为了估计参数θ \theta θ X X X x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x 1 , x 2 , ... , x n Y Y Y y 1 , y 2 , . . . , y n y_1,y_2,...,y_n y 1 , y 2 , ... , y n y = f ( x , θ ) y=f(x,\theta) y = f ( x , θ )
这一"数据拟合"过程的常用实现方法就是最小二乘法 ,即取使得
χ 2 ( θ ) ≡ ∑ i = 1 N [ y i − f ( x i ; θ ) ] 2 \chi^2(\theta)\equiv\sum_{i=1}^N[y_i-f(x_i;\theta)]^2
χ 2 ( θ ) ≡ i = 1 ∑ N [ y i − f ( x i ; θ ) ] 2
达到最小值的θ ^ \hat{\theta} θ ^
若在不同x i x_i x i y i y_i y i y i y_i y i σ i 2 \sigma_i^2 σ i 2 χ 2 ( θ ) \chi^2(\theta) χ 2 ( θ )
χ 2 ( θ ) ≡ ∑ i = 1 N [ y i − f ( x i ; θ ) ] 2 σ i 2 \chi^2(\theta)\equiv\sum_{i=1}^N\frac{[y_i-f(x_i;\theta)]^2}{\sigma_i^2}
χ 2 ( θ ) ≡ i = 1 ∑ N σ i 2 [ y i − f ( x i ; θ ) ] 2
y i y_i y i χ 2 ( θ ) \chi^2(\theta) χ 2 ( θ )
在Y Y Y 指数族分布 (泊松,伽马,正态,二项等)的前提下,其参数估计的迭代重加权最小二乘法 等价于最大似然法.
L18 区间估计
L19 假设检验
L20 方差分析
L21 回归分析
L22 泊松回归
L23 自助法
L24 贝叶斯统计
L25 随机过程
L26 维纳过程
L27 马尔可夫过程
L28 测量不确定度
L29 平稳随机过程